简介
根据调度实体统计的历史负载数据 计算当前系统瞬时负载
v3.8之前的负载统计方式是基于队列的 per cfs-rq, 实际上并不清楚负载究竟来自哪个任务
pelt处理方式,跟踪记录每一个调度实体的负载,运行队列 cfs-rq 负载来源于队列中所有成员的负载总和
好处
- 跟踪的粒度更小,更精确,调度器可以清晰的掌握每一个任务对系统的负载贡献度
- 没有增加调度开销,并没有记录保存每一个历史周期的负载数值。
- 负载均衡调整时,任务在cpu之间迁移时更容易计算效能
- 动态电压频率调整,电源管理器更容易统计出需要多少算力(消耗多少电量)
衰减公式
负载是一个瞬时量,时间越靠近当下,影响越大,负载贡献度越高,时间越久远,影响越小,负载贡献度越低
衰减因子就用于在时间维度上调节负载贡献值
负载统计衰减公式
L = L0 + L1y + L2y^2 + L3y^3 + … + Lny^n
在3.8版本的代码中,y已经确定:y^32 = 0.5
L0 是当前时间的load,y是衰减因子,Ln是基于now往前第n个period的load
实际上 L1 = L2 = … Ln ≈ 1ms(运行时间)
跟踪时间粒度大小为1024us,即以1024us(约等于1ms)为一个周期,
这样选定的y值,一个调度实体的负荷贡献经过32个周期后,对当前时间的的负载贡献值会衰减一半。
跟踪和更新负载从最初运行开始一直都只是保存了一个统计数据,后续更新都是在此数值基础上的乘法运算,都是针对一个数值在更新,不需要使用数组来记录过去的负载贡献,所以并没有保存多余的数据, 只要把上次的负载总和的贡献值乘以y再加上新的负载L0就可以了
更新负载的时机
- 加入运行队列
- 离开运行队列
- 周期性调度器
相关代码
struct sched_avg {
u64 last_update_time, load_sum;
u32 util_sum, period_contrib;
unsigned long load_avg, util_avg;
};
跟踪调度实体的负载
- last_update_time 上次负载统计时间,单位ns
- load_sum 基于runnable时间的负载贡献总和,包括 在rq上runnable等待运行时间 和 在cpu上的running运行时间的 负载贡献总和
- util_sum 在cpu上的running运行时间的负载贡献总和
- period_contrib 初始值为1023, 更新负载过程用于保存上一次更新负载之后,没有达到一个周期的1024us的一个余数
- load_avg 基于runnable时间的平均负载贡献
- util_avg 基于running时间的平均负载贡献
优化常量
static const u32 runnable_avg_yN_inv[] = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
runnable_avg_yN_inv 的每个元素分别表示从当前到过去32个period对应的衰减因子
之所以每个元素数值是当前这种形式,是因为内核为避免浮点运算,把负载计算时涉及到的浮点运算转换成了乘法运算,而且乘法运算使用的乘数也已经计算好了,就是runnable_avg_yN_inv数组的各个元素值.
因为规定y^32 = 0.5 即过去第32个毫秒的负载衰减因子约为0.5
转换为乘数,即runnable_avg_yN_inv[31],就是 0x82cd8698
换算 0x82cd8698 / pow(2, 32) = 0.511 ≈ 0.5
以此类推其余各个元素值
static const u32 runnable_avg_yN_sum[] = {
0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103,
9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082,
17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371,
};
根据衰减因子预先计算好在不超过32个周期时对应的负载贡献度总和
runnable_avg_yN_inv[1] 0xfa83b2da / pow(2, 32) ≈ 0.978
runnable_avg_yN_inv[2] 0xf5257d14 / pow(2, 32) ≈ 0.957
runnable_avg_yN_sum[2] = 1024(us) * (0.978 + 0.957) ≈ 1982
__update_load_avg v4.4
static __always_inline int
__update_load_avg(u64 now, int cpu, struct sched_avg *sa,
unsigned long weight, int running, struct cfs_rq *cfs_rq)
{
u64 delta, scaled_delta, periods;
u32 contrib;
unsigned int delta_w, scaled_delta_w, decayed = 0;
unsigned long scale_freq, scale_cpu;
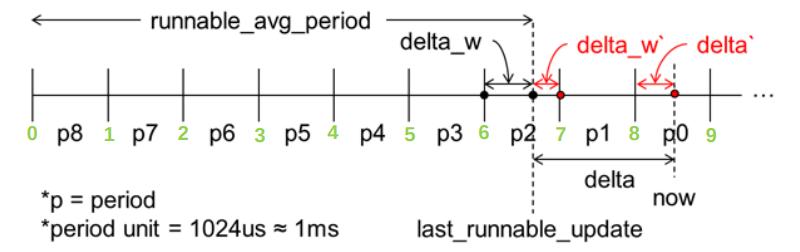
delta = now - sa->last_update_time; // 增量运行时间 图中所示delta = (delta_w` + [0,n]*period + delta`)
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10; // 转换为us微妙单位
if (!delta)
return 0;
sa->last_update_time = now; // 记录本次更新时间
scale_freq = arch_scale_freq_capacity(NULL, cpu);
scale_cpu = arch_scale_cpu_capacity(NULL, cpu);
/* delta_w is the amount already accumulated against our next period */
delta_w = sa->period_contrib; // 上一次更新时不足一个周期的余数
if (delta + delta_w >= 1024) { // 超过一个周期period 1ms
decayed = 1; // 超过一个周期,需要衰减
/* how much left for next period will start over, we don't know yet */
sa->period_contrib = 0;
/*
* Now that we know we're crossing a period boundary, figure
* out how much from delta we need to complete the current
* period and accrue it.
*/
delta_w = 1024 - delta_w; // 即图中 delta_w`
scaled_delta_w = cap_scale(delta_w, scale_freq);
if (weight) { // load [0 - prev] prev包含了delta_w` 是period整数倍
sa->load_sum += weight * scaled_delta_w;
if (cfs_rq) {
cfs_rq->runnable_load_sum +=
weight * scaled_delta_w;
}
}
if (running)
sa->util_sum += scaled_delta_w * scale_cpu;
delta -= delta_w; // 减去图中余数delta_w`
/* Figure out how many additional periods this update spans */
periods = delta / 1024; // 整数倍period个数
delta %= 1024; // 不到一个周期,多出的余数,对应图中 delta`
sa->load_sum = decay_load(sa->load_sum, periods + 1); // 衰减负载 [0 - prev] prev包含了delta_w` 是period整数倍
if (cfs_rq) {
cfs_rq->runnable_load_sum =
decay_load(cfs_rq->runnable_load_sum, periods + 1); // cfs_rq负载衰减
}
sa->util_sum = decay_load((u64)(sa->util_sum), periods + 1);
/* Efficiently calculate \sum (1..n_period) 1024*y^i */
contrib = __compute_runnable_contrib(periods); // 计算连续periods
个周期的累计负载贡献值
contrib = cap_scale(contrib, scale_freq);
if (weight) {
sa->load_sum += weight * contrib; // 更新sa负载总和
if (cfs_rq)
cfs_rq->runnable_load_sum += weight * contrib; // 更新cfs_rq负载总和
}
if (running) // running 负载
sa->util_sum += contrib * scale_cpu;
}
/* Remainder of delta accrued against u_0` */
scaled_delta = cap_scale(delta, scale_freq); // 对应图中 delta`
if (weight) { // load of [0 - now]
sa->load_sum += weight * scaled_delta; // 加上剩余不足一个周期的负载贡献值
if (cfs_rq)
cfs_rq->runnable_load_sum += weight * scaled_delta;
}
if (running)
sa->util_sum += scaled_delta * scale_cpu;
sa->period_contrib += delta; // 记录不足一个周期的余数,下次更新负载时使用,对应图中 delta`
if (decayed) { // 平均负载
sa->load_avg = div_u64(sa->load_sum, LOAD_AVG_MAX);
if (cfs_rq) {
cfs_rq->runnable_load_avg =
div_u64(cfs_rq->runnable_load_sum, LOAD_AVG_MAX);
}
sa->util_avg = sa->util_sum / LOAD_AVG_MAX;
}
return decayed;
}
[参考链接]
https://lwn.net/Articles/513135/
https://lwn.net/Articles/531853/
http://www.wowotech.net/process_management/PELT.html
http://www.wowotech.net/process_management/450.html
http://osdc.hanyang.ac.kr/sitedata/2015_Linux_Seminar/5_Per_entity_Load_Tracking.pdf