简介
在多核执行环境,原子操作指令对于内存共享内存的并发访问保护至关重要。
也是实现其它高级并发元语的基础。比如semaphore/mutex/spinlock/rwlock等。
高级并发元语锁竞争的公平性,由软件来保证。
Complex Instruction Set Computer(CISC)
复杂指令集架构会提供读-修改-写的指令,保证读写同一块内存时的原子性。
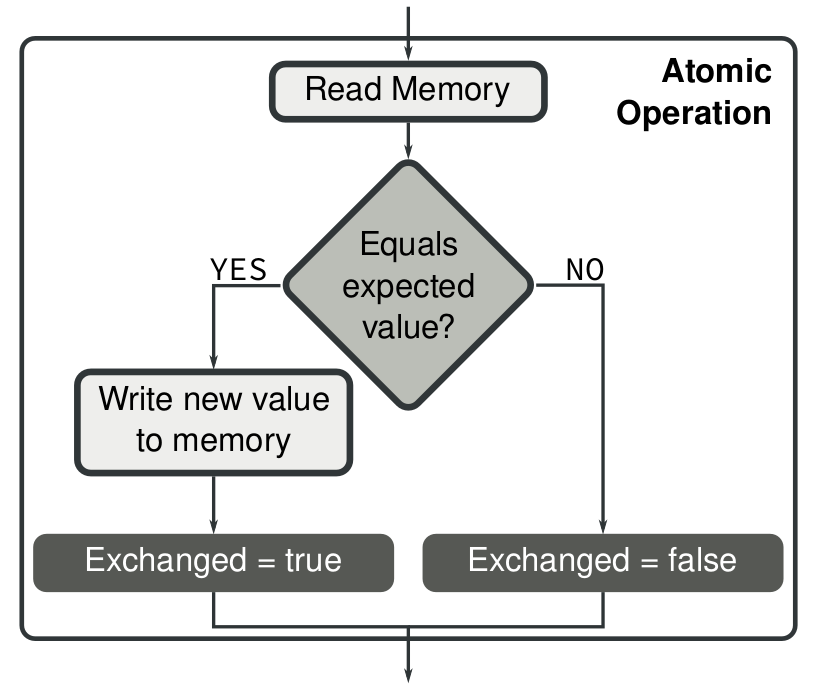
一个显著的例子就是CAS指令(Compare-and-Swap).
CAS(memaddr, expected, new)
memaddr位置保存的数据如果等于expected,就把new值存写入memaddr。
比如intel x86的cmpxchg指令。
Reduced Instruction Set Computer(RISC)
精简指令集架构为了避免复杂的实现,
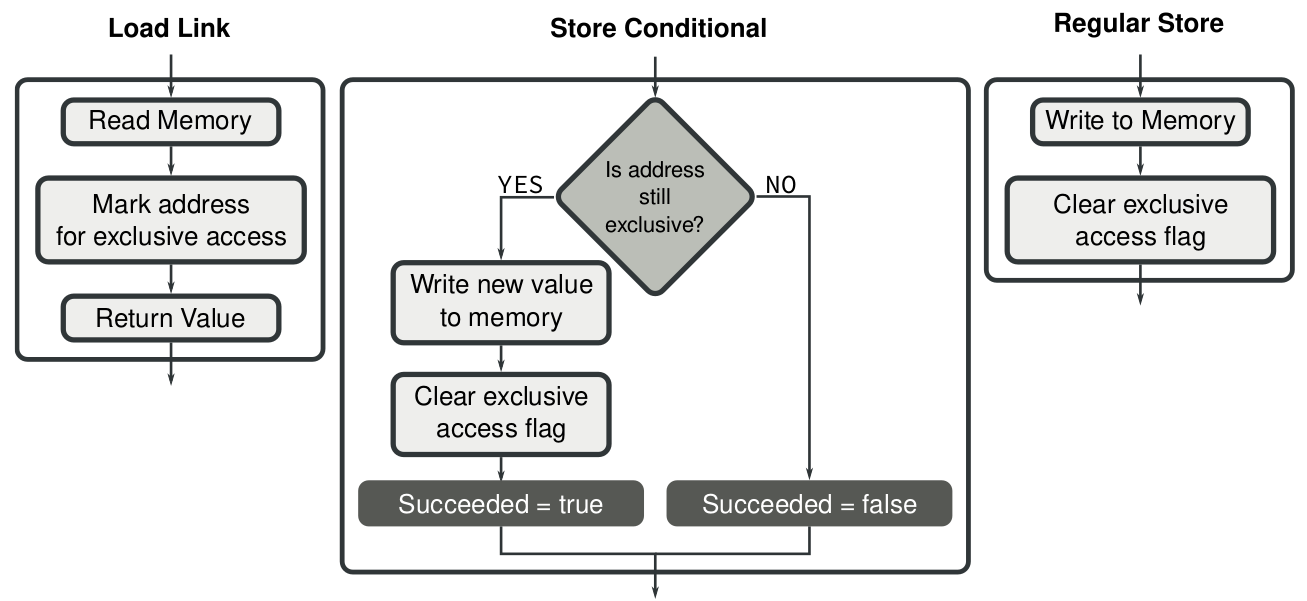
把整个CAS过程分解为Load-Link(LL)和Store-conditional(SC)两条指令.
软件应用时,两条指令成对出现,外加一个循环逻辑来保证原子性。
如果出现访存冲突,循环检测尝试写入。
这就是LL/SC保证原子性的指令序列。
LL指令读内存数据,把对应的内存位置标记为独占访问。
SC指令完成写入操作,但是前提条件是,只有在当前核执行LL指令以来,其它核没有发生写入。
多个核同时执行SC指令,只有一个会成功,失败的核会重新执行LL/SC指令序列。
常规存储指令写数据到内存时会自动清除独占标记,所以会被SC检测到这种情况。
一旦发现标记被清除,SC执行失败,否则SC写入成功。
比如arm的ldxr/stxr指令及其变种,mips的ll/sc指令。
hardware implementation
x86架构
总线锁和缓存一致性共同实现系统内存原子操作。
x86处理器三种机制保证原子性
- 基础操作保证原子性,比如读写一个字节,读写16bit对齐的字,读写32bit对齐的双字等等。
- 总线锁 使用LOCK信号和LOCK指令前缀
- 缓存一致性协议(多核之间的一种通信协议)保证被缓存在各级缓存中的数据一致性
第一条是硬件可以完全保证的。一旦有一个核读写某个内存位置,在本次读写完成之前,其他核的读写不会得到响应。
处理器也支持锁住总线,保证指定区间范围内内存操作的原子性。
事实上,因为频繁存取的数据很有可能缓存在L1或者L2 cache里,原子性操作的作用范围就会局限在处理器缓存,
而无需锁住总线,处理器缓存一致性协议会保证针对这部分内存区域写操作的原子性。
bus lock
总线锁原子性不受对齐的影响,即对不对齐都能保证原子性。
总线锁为了保证指定大小内存区域的内存操作的原子性,可能会占用尽可能多的总线周期。
所以为了性能起见,建议按照自然边界对齐。
- Any boundary for an 8-bit access (locked or otherwise).
- 16-bit boundary for locked word accesses.
- 32-bit boundary for locked doubleword accesses.
- 64-bit boundary for locked quadword accesses.
Automatic Locking 自动锁
在以下场合处理器会自动使能锁总线(intel manual vol3 8.1.2.1)
- When executing an XCHG instruction that references memory.
- When setting the B (busy) flag of a TSS descriptor
- When updating segment descriptors
- When updating page-directory and page-table entries
- Acknowledging interrupts
Software Controlled Bus Locking 软件可控的锁
软件在以下场合可以控制处理器使能锁总线(intel manual vol3 8.1.2.2)
- The bit test and modify instructions (BTS, BTR, and BTC).
- The exchange instructions (XADD, CMPXCHG, and CMPXCHG8B).
- The LOCK prefix is automatically assumed for XCHG instruction.
- The following single-operand arithmetic and logical instructions: INC, DEC, NOT, and NEG.
- The following two-operand arithmetic and logical instructions: ADD, ADC, SUB, SBB, AND, OR, and XOR
x86原子指令自带内存屏障效果,会导致cpu冲刷流水线,会导致多核间频繁修改的共享数据在data cache中无效化, 总的来说对性能是有影响的。
cmpxchg指令
81 static __always_inline int queued_spin_trylock(struct qspinlock *lock)
82 {
83 if (!atomic_read(&lock->val) &&
84 (atomic_cmpxchg(&lock->val, 0, _Q_LOCKED_VAL) == 0))
85 return 1; // 持锁成功返回1
86 return 0; // 持锁失败返回0
87 }
110 static void __spin_lock_debug(raw_spinlock_t *lock)
111 {
112 u64 i;
113 u64 loops = loops_per_jiffy * HZ;
114
115 for (i = 0; i < loops; i++) { // for循环,尝试多次
116 if (arch_spin_trylock(&lock->raw_lock))
117 return; // 持锁成功返回
118 __delay(1);
119 }
...
137 void do_raw_spin_lock(raw_spinlock_t *lock)
138 {
139 debug_spin_lock_before(lock);
140 if (unlikely(!arch_spin_trylock(&lock->raw_lock)))
141 __spin_lock_debug(lock);// 失败进入for循环,继续尝试
142 debug_spin_lock_after(lock); // 成功拿到锁
143 }
do_raw_spin_lock反汇编片段
0xffffffff810aa2dd <+61>: je 0xffffffff810aa3bf <do_raw_spin_lock+287>
0xffffffff810aa2e3 <+67>: mov (%rbx),%eax // 从内存取出lock的值放到eax
0xffffffff810aa2e5 <+69>: test %eax,%eax // 判断lock 是否为0
0xffffffff810aa2e7 <+71>: jne 0xffffffff810aa2f6 <do_raw_spin_lock+86> // 不为0表示被占用,跳转;为0,继续执行,尝试拿锁
0xffffffff810aa2e9 <+73>: mov $0x1,%edx // 为0,没被占用
0xffffffff810aa2ee <+78>: lock cmpxchg %edx,(%rbx) // 原子指令尝试持锁
0xffffffff810aa2f2 <+82>: test %eax,%eax // 判断结果
0xffffffff810aa2f4 <+84>: je 0xffffffff810aa35d <do_raw_spin_lock+189> // 为0表示持锁成功,跳转
0xffffffff810aa2f6 <+86>: imul $0x3e8,0x97bd4f(%rip),%r14 # 0xffffffff81a26050 <loops_per_jiffy> // 持锁失败,进入for循环
0xffffffff810aa301 <+97>: xor %r12d,%r12d
arm架构
The A64 instruction set has instructions for implementing such synchronization functions:
Load Exclusive (LDXR): LDXR W Xt, [Xn]
Store Exclusive (STXR): STXR Ws, W Xt, [Xn] where Ws indicates whether the store completed successfully. 0 = success. - Clear Exclusive access monitor (CLREX) This is used to clear the state of the Local Exclusive Monitor.
ldxr从内存加载数值,同时当前核标记该物理地址独占访问。
stxr根据检测条件保存数值到内存,只有检测到目标内存位置被当前核标记为独占访问,才会写入成功。
stxr执行完毕,执行成功与否的状态值会保存到Ws寄存器,为0表示写入成功,非0表示写入失败。
stxr会清除独占标记。
独占标记并不能阻止其它核读写该内存位置,只是监测该位置自从上次执行LDXR以来是否被写入过。
do_raw_spin_lock 汇编片段
0xffff0000200fe96c <+396>: prfm pstl1strm, [x19] // 0 static inline void arch_spin_lock(arch_spinlock_t *lock)
0xffff0000200fe970 <+400>: ldaxr w0, [x19] // 1
0xffff0000200fe974 <+404>: add w1, w0, #0x10, lsl #12 // 2
0xffff0000200fe978 <+408>: stxr w2, w1, [x19] // 3
0xffff0000200fe97c <+412>: cbnz w2, 0xffff0000200fe970 <do_raw_spin_lock+400> // 4
0xffff0000200fe980 <+416>: eor w1, w0, w0, ror #16 // w1 = w0 ^ (w0 >> 16) 0x00010001 ^ 0x00010001 == 0
0xffff0000200fe984 <+420>: cbz w1, 0xffff0000200fe99c <do_raw_spin_lock+444>
arch_spin_lock内联到了do_raw_spin_lock
- 自旋锁seq序列号加载到w0 w0 00020001
- 持锁时序列号加+1 w1 = w0 + 0x00010000(next++) 00030001 上一个线程释放之后变为00030002
- 新序列号写回内存
- 检测写入是否成功,失败跳转到offset==400位置继续循环;成功则继续往下执行
mips架构
_raw_spin_lock 汇编片段
0xffffffff803d7238 _raw_spin_lock <+280>: move v0,zero
0xffffffff803d723c _raw_spin_lock <+284>: nop
0xffffffff803d7240 _raw_spin_lock <+288>: ll a0,0(s0) // 1
0xffffffff803d7244 _raw_spin_lock <+292>: ori v1,a0,0x1 // 2
0xffffffff803d7248 _raw_spin_lock <+296>: sc v1,0(s0) // 3
0xffffffff803d724c _raw_spin_lock <+300>: sll zero,zero,0x3 //
0xffffffff803d7250 _raw_spin_lock <+304>: beqz v1,0xffffffff803d7348 _raw_spin_lock <+552> // 4
0xffffffff803d7254 _raw_spin_lock <+308>: andi v1,a0,0x1
0xffffffff803d7258 _raw_spin_lock <+312>: sync // 5
0xffffffff803d725c _raw_spin_lock <+316>: beqz v1,0xffffffff803d71a0 _raw_spin_lock <+128>
0(s0) 所有核共享的lock变量内存位置,存储值为0表示锁处于空闲状态,为1表示已经被某个核获取,其余核想获取只能等待
- lock变量读入a0寄存器
-
v1 = a0 0x1 持锁 - v1寄存器的值存入lock,并将返回操作结果写到v1
- v1值为0, 表示3中的操作失败,跳转到offset 为552的位置,重新开始获取操作 v1 值为1,表示获取锁操作成功,继续执行后续指令,函数即将返回
- 内存操作同步指令,用于保证sync之前对于内存的操作能够在sync之后的指令开始之前完成
[参考]
- intel-manual-vol-1-2abcd-3abcd.pdf
- ARM Cortex-A Series Programmer’s Guide for ARMv8-A