实时内核提高实时性的关键在于降低延迟
PREEMPT_RT主要是想尽可能的达成如下两个目标
-
降低中断响应延迟(中断线程化)
大多数硬中断实现极为精简,每个架构相关代码都只有几十行,减少了禁中断的时间
只负责配置中断控制器,屏蔽中断请求线,确认中断,然后就返回,剩余任务都交给中断线程去处理
硬中断返回了就可以及时调度高优先级实时任务
中断线程执行的时候,开中断,也可以被抢占,就可以及时响应新的中断 -
降低调度延迟(临界区可抢占)
实时内核spin_lock_xxx(还包括rwlock/semaphore/rcu-reader)系列接口既可以被抢占,也不再禁中断
确实需要禁抢占,禁中断的场合要用raw_spin_lock_xxx系列接口(一般驱动用不到,极少场合才会用到)
所以高优先级的实时任务到来时可以及时得到调度
PREEMPT_RT 内核的实时性不能通过理论严格论证,只能做实验性质的评估。
COST硬件不可预知,再加上不可能计算到所有代码控制路径和所有可能的干扰源,所以很难计算出延迟和WCET的上限。
IO操作也会带来临时性不确定延迟,不但取决于硬件,也取决于驱动实现。
IPC进程间通信也会影响到实时性,因为需要利用同步手段在不同的进程地址空间共享数据,包括网络通信。
延迟构成-软件因素
- 响应中断延迟
- 中断处理耗时
- 调度决策延迟
- 调度器耗时
延迟构成-硬件因素
- System Management Interrupt (SMI)
- Cache miss (instruction cache, data cache)
- Branch prediction
- Hyper-threading - Simultaneous multithreading (SMT)
- Page fault / Translation Lookaside Buffer (TLB)
上下文的划分
非实时内核有三个上下文
- interrupt context(non-preemptible)
- software interrupt context(non-preemptible)
- process context(preemptible,但是位于临界区时不可被抢占,又称原子上下文)
实时内核有四个上下文
- hardware interrupt context(non-preemptible)
- interrupt context(fully-preemptible)
- software interrupt context(fully-preemptible)
- process context(fully-preemptible)
内核抢占模型
| 配置项 | 解释说明 |
|---|---|
| CONFIG_PREEMPT_NONE | No Forced Preemption (Server) |
| CONFIG_PREEMPT_VOLUNTARY | Voluntary Kernel Preemption (Desktop) |
| CONFIG_PREEMPT | Preemptible Kernel (Low-Latency Desktop) |
| CONFIG_PREEMPT_RT | Fully Preemptible Kernel (Real-Time) |
-
CONFIG_PREEMPT_NONE
传统的抢占模型,目标是使吞吐量最大化。对实时性没有保证,可能会出现长延迟
主要用于服务器和科学计算系统。如果希望内核的处理能力最大化,不考虑调度延迟,就选这个模型 -
CONFIG_PREEMPT_VOLUNTARY
通过在内核里选择性的增加一些抢占点来减小延迟
当低优先级进程在内核模式执行的时候,可以在预定的抢占点自愿被抢占
减小最大调度延迟和对交互式事件提供更快的响应,主要用于桌面系统 -
CONFIG_PREEMPT
非临界区内核路径(that is not executing in a critical section)都可以被抢占
主要用于低延迟桌面系统或者嵌入式系统,最坏情况延迟时间几毫秒 -
CONFIG_PREEMPT_RT
把自旋锁和读写锁替换为可以抢占的、支持优先级继承的锁,强制中断线程化,并且引入各种机制来打破长的、不可抢占的临界区。
主要用于延迟要求为100微秒或稍低(几十微秒)的实时系统
调度策略
先进先出调度和轮流调度的主要区别是对优先级相同的实时进程的处理策略不同:
前者不会把处理器让给优先级相同的实时进程,后者会把处理器让给优先级相同的实时进程
实时调度器
需要考虑系统中所有实时进程,根据紧急程度为每个实时进程选择合适的优先级
-
SCHED_FIFO
先进先出调度,如果没有更高优先级的实时进程并且不睡眠,那么会一直占据cpu -
SCHED_RR
轮流调度,进程用完时间片后加入优先级对应的运行队列的尾部,把处理器让给优先级相同的其它实时进程 -
SCHED_DEADLINE
限期调度器涉及三个参数: 运行时间runtime、截止期限deadline和调度周期period
只依赖应用程序自身,不需要考虑系统中其他的实时进程
非实时内核影响实时性的因素
- 正在执行中断处理程序
- 正在执行禁中断的临界区
— 应对方法 —
-
中断线程化, 使用内核线程执行中断处理函数,那么原来禁止硬中断的临界区就不需要禁止硬中断
为了兼顾非实时内核和实时内核,引入本地锁
非实时内核把本地锁映射到禁止内核抢占和禁止硬中断,实时内核把本地锁映射到基于实时互斥锁实现的自旋锁 -
为了减少时钟中断处理程序的执行时间,把高精度定时器的到期模式分为软中断到期模式和硬中断到期模式
使得大多数高精度定时器使用软中断到期模式,在软中断上下文处理
实时进程不能被及时调度的因素
- 正在执行软中断
- 正在执行禁止软中断的临界区(local_bh_disable)
- 正在执行禁止内核抢占的临界区(preempt_disable)
- 正在执行RCU保护的读断临界区,禁止内核抢占(rcu_read_lock/rcu_read_lock_bh)
- 正在执行自旋锁或者读写锁保护
- 需要申请的锁(包括互斥锁、伤害/等待互斥锁和读写信号量)被低优先级的进程持有,导致优先级高的进程等待优先级低的进程,发生优先级反转
— 应对方法 —
- 软中断全部由软中断线程执行,那么原来禁止软中断的临界区可以变成可抢占的,和软中断线程使用本地锁互斥
- 在实时内核中大多数禁止内核抢占的临界区可以变成可抢占的,为了兼顾非实时内核和实时内核,引入本地锁
非实时内核把本地锁映射到禁止内核抢占和禁止硬中断,实时内核把本地锁映射到使用实时互斥锁实现的自旋锁 - 实现可抢占RCU,把RCU读断临界区变成可抢占的
- 把自旋锁和读写锁替换为可抢占的、支持优先级继承的锁
- 互斥锁、伤害/等待互斥锁、读写信号量 支持优先级继承
实时进程执行的时候影响实时性的因素
- linux内核使用虚拟内存,对用户空间的内存(栈、代码段、数据段以及使用malloc或mmap动态分配的内存)使用惰性分配的策略
如果实时进程访问的虚拟页没有映射到物理页,那么会触发缺页异常,影响实时性 - linux内核在内存不足的时候会回收物理页,导致实时进程访问的虚拟页没有映射到物理页,影响实时性
— 应对方法 —
实时进程在main函数里使用malloc/mmap预先分配内存,并且调用函数mlockall,把所有虚拟页映射到物理页,锁定在内存中,阻止内核回收这些物理页
提高实时性的策略
强制中断线程化
使用内核线程执行中断处理函数,内核线程名称 irq/
int request_threaded_irq(unsigned int irq,
irq_handler_t handler, // 主函数,硬中断上下文被调用
irq_handler_t thread_fn, // 如果需要进一步处理,handler会唤醒中断处理线程,执行thread_fn指定的函数
unsigned long irqflags,
const char *devname,
void *dev_id)
参数handler指定主函数,主函数在硬中断上下文里面被调用,需要检查中断是不是对应的外围设备发送的。
如果中断是对应的外围设备发送的,那么handler函数返回IRQ_HANDLED或IRQ_WAKE_THREAD。
如果不需要进一步的处理,那么返回IRQ_HANDLED。
如果需要进一步的处理,那么返回IRQ_WAKE_THREAD,中断处理程序将会唤醒中断处理线程,执行参数thread_fn指定的函数
参数thread_fn指定中断处理线程调用的函数。如果参数thread_fn是空指针,那么不创建中断处理线程。
少数中断不能线程化,典型的例子是时钟中断。对于不能线程化的中断,注册处理函数的时候必须设置标志IRQF_NO_THREAD。
static inline int __must_check
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, // 兼容旧的驱动,只提供handler,不会提供thread_fn
const char *name, void *dev)
{
return request_threaded_irq(irq, handler, NULL, flags, name, dev); // thread_fn为NULL
}
request_threaded_irq(irq, handler, thread_fn, ...)
if (!handler) {
if (!thread_fn)
return -EINVAL;
handler = irq_default_primary_handler; // irq_default_primary_handler直接返回IRQ_WAKE_THREAD
}
request_threaded_irq
__setup_irq
setup_irq_thread
kthread_create // 创建线程
sched_setscheduler_nocheck(t, SCHED_FIFO, ¶m); // 设置调度策略
new->thread = get_task_struct(t); //
handle_irq_event_percpu
__handle_irq_event_percpu
action->handler
__irq_wake_thread // IRQ_WAKE_THREAD
wake_up_process(action->thread);
irq_thread /// Interrupt handler thread
高精度定时器
软中断到期模式
HRTIMER_MODE_SOFT - Timer callback function will be executed in soft irq context
到期的时候在类型为HRTIMER_SOFTIRQ的软中断里面执行定时器回调函数
硬中断到期模式
HRTIMER_MODE_HARD - Timer callback function will be executed in hard irq context even on PREEMPT_RT.
到期的时候在时钟中断处理程序里面执行定时器回调函数
如果没有指定到期模式,那么在实时内核中默认使用软中断到期模式
版本5.4内核主线支持软实时做准备,增加HRTIMER_MODE_HARD
- 如果把到期模式指定为HRTIMER_MODE_HARD,那么在硬中断里面执行定时器回调函数,即使在实时内核中也是这样做。
- 如果没有指定到期模式,那么在非实时内核中默认使用硬中断到期模式,在实时内核中默认使用软中断到期模式。
为了减小时钟中断处理程序的执行时间,大多数高精度定时器应该使用软中断到期模式;少数高精度定时器必须使用硬中断到期模式
- 必须在硬中断里面执行,例如进程调度器周期性地调度进程。
- 对延迟很敏感,例如函数nanosleep()把睡眠时间精确到纳秒。
软中断线程化
-
非实时内核
一部分软中断在中断处理程序的后半部分执行,有时间限制,最多执行10轮(MAX_SOFTIRQ_RESTART),并且总时间不超过2ms(MAX_SOFTIRQ_TIME)。
剩下的软中断由软中断线程执行,或者在进程开启软中断(local_bh_enable)的时候执行。
每个cpu核有一个自己的软中断线程,名字是 ksoftirqd/cpu,调度策略是SCHED_NORMAL,优先级是120 -
实时内核
软中断由软中断线程执行,或者在进程开启软中断的时候执行。中断处理程序的后半部分唤醒当前cpu核的软中断线程
软中断和用户实时进程,谁的优先级应该更高一些,可能需要结合实际业务逻辑
具体谁比谁设置优先级更高,得采取不同的策略,要么软中断更高,要么用户实时进程更高。
#ifdef CONFIG_PREEMPT_RT // 实时内核
static inline void invoke_softirq(void)
{
if (this_cpu_read(softirq_counter) == 0) // softirq_counter 为0时表示当前cpu核没有唤醒过ksoftirqd/<cpu>
wakeup_softirqd(); // 唤醒ksoftirqd处理软中断
}
#else //非实时内核
static inline void invoke_softirq(void)
{
if (ksoftirqd_running(local_softirq_pending())) //当前核上的ksoftirqd已经被唤醒,则直接返回
return;
if (!force_irqthreads) {
#ifdef CONFIG_HAVE_IRQ_EXIT_ON_IRQ_STACK
/*
* We can safely execute softirq on the current stack if
* it is the irq stack, because it should be near empty
* at this stage.
*/
__do_softirq(); // 马上处理软中断
#else
/*
* Otherwise, irq_exit() is called on the task stack that can
* be potentially deep already. So call softirq in its own stack
* to prevent from any overrun.
*/
do_softirq_own_stack();
#endif
} else {
wakeup_softirqd(); // 强制中断线程化的情况下,唤醒软中断线程处理软中断
}
}
#endif
解决RCU读端临界区不能抢占问题
Linux内核支持3种RCU
- 不可抢占RCU(RCU-sched),不允许进程在读端临界区被其他进程抢占。
- 加速版不可抢占RCU(RCU-bh)是针对不可抢占RCU的改进,在软中断很多的情况可以缩短宽限期。
- 可抢占RCU(RCU-preempt),也称为实时RCU。可抢占RCU允许进程在读端临界区被其他进程抢占。
编译内核时需要开启配置宏CONFIG_PREEMPT_RCU
4.20版本做了修改:在非抢占式内核中把RCU-bh、RCU-preempt和RCU-sched合并为RCU-sched,
在抢占式内核中把RCU-bh、RCU-preempt和RCU-sched合并为RCU-preempt。
rcu_read_lock()、rcu_read_unlock() 和call_rcu()这些函数使用可抢占RCU实现
所以使用rcu_read_lock()和rcu_read_unlock()保护的读端临界区是可以抢占的。
如果读端临界区绝对不能被抢占,那么应该使用不可抢占RCU提供的函数rcu_read_lock_sched()和rcu_read_unlock_sched()保护临界区
函数rcu_read_lock_sched()禁止内核抢占,函数rcu_read_unlock_sched()开启内核抢占。
在实时内核中,软中断全部由软中断线程执行,RCU-bh保护的读端临界区是可以抢占的,只需和当前处理器上的软中断线程互斥
RCU-bh使用函数rcu_read_lock_bh()和rcu_read_unlock_bh()保护读端临界区
rcu_read_lock_bh() 等价于“rcu_read_lock() + 禁止软中断”,
rcu_read_unlock_bh()等价于“rcu_read_unlock() + 开启软中断”
#ifdef CONFIG_PREEMPT_RT
extern void __local_bh_disable_ip(unsigned long ip, unsigned int cnt);
#else
#ifdef CONFIG_TRACE_IRQFLAGS
extern void __local_bh_disable_ip(unsigned long ip, unsigned int cnt);
#else
static __always_inline void __local_bh_disable_ip(unsigned long ip, unsigned int cnt)
{
preempt_count_add(cnt); //非实时内核,只需要禁止当前cpu核心软中断即可
barrier();
}
#endif
#endif
static inline void rcu_read_lock_bh(void)
{
local_bh_disable();
__acquire(RCU_BH);
rcu_lock_acquire(&rcu_bh_lock_map);
RCU_LOCKDEP_WARN(!rcu_is_watching(), "rcu_read_lock_bh() used illegally while idle");
}
static inline void local_bh_disable(void)
{
__local_bh_disable_ip(_THIS_IP_, SOFTIRQ_DISABLE_OFFSET);
}
#ifdef CONFIG_PREEMPT_RT
void __local_bh_disable_ip(unsigned long ip, unsigned int cnt)
{
unsigned long __maybe_unused flags;
long soft_cnt;
WARN_ON_ONCE(in_irq());
if (!in_atomic()) { // 非原子上下文
local_lock(bh_lock); // per-cpu 当前cpu核上的互斥锁,和其他软中断上下文互斥
rcu_read_lock(); // 标记进入 rcu读端临界区,实时内核允许抢占
}
soft_cnt = this_cpu_inc_return(softirq_counter); // 进入softirq时自增
WARN_ON_ONCE(soft_cnt == 0);
current->softirq_count += SOFTIRQ_DISABLE_OFFSET; // 标记current进程进入软中断上下文
#ifdef CONFIG_TRACE_IRQFLAGS
local_irq_save(flags);
if (soft_cnt == 1)
trace_softirqs_off(ip);
local_irq_restore(flags);
#endif
}
#else // 非实时内核
void __local_bh_disable_ip(unsigned long ip, unsigned int cnt)
{
unsigned long flags;
WARN_ON_ONCE(in_irq());
raw_local_irq_save(flags); // 关中断
/*
* The preempt tracer hooks into preempt_count_add and will break
* lockdep because it calls back into lockdep after SOFTIRQ_OFFSET
* is set and before current->softirq_enabled is cleared.
* We must manually increment preempt_count here and manually
* call the trace_preempt_off later.
*/
__preempt_count_add(cnt);
/*
* Were softirqs turned off above:
*/
if (softirq_count() == (cnt & SOFTIRQ_MASK))
trace_softirqs_off(ip);
raw_local_irq_restore(flags);
if (preempt_count() == cnt) {
#ifdef CONFIG_DEBUG_PREEMPT
current->preempt_disable_ip = get_lock_parent_ip();
#endif
trace_preempt_off(CALLER_ADDR0, get_lock_parent_ip());
}
}
rcu_nocbs
RCU callback影响实时性,执行在中断上下文的callback会带来不可忽略的延迟。 Sarma 和 McKenney 引入了 CONFIG_RCU_NOCB_CPU 和 rcu_nocbs 参数,把callback的执行推到了对时限要求不高的内核线程中。
解决优先级反转问题
什么是优先级反转(priority inversion)?
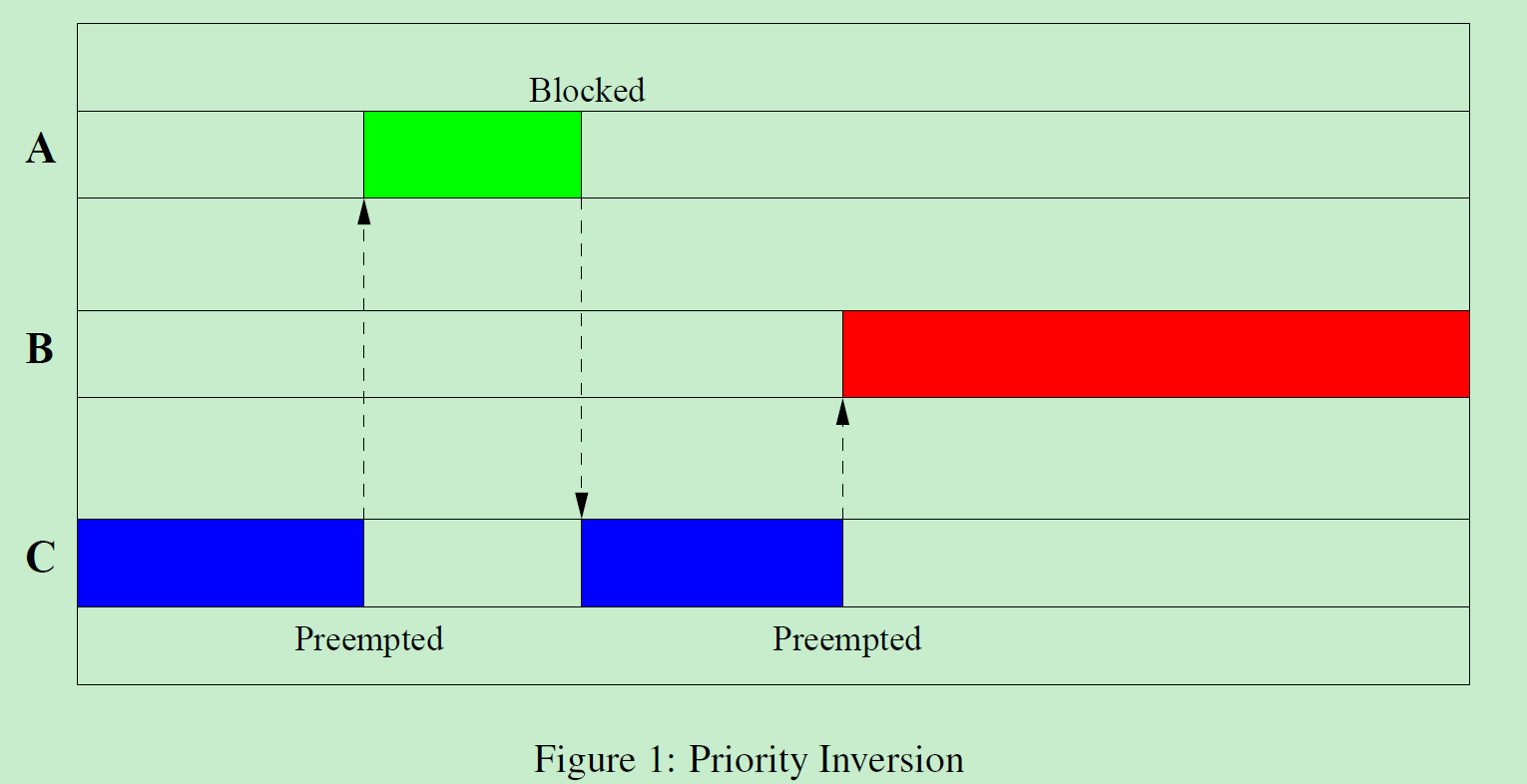
假设进C的优先级低,进程的A优先级高。进程C持有互斥锁,进程A申请互斥锁,
因为进程C已经占有互斥锁,所以进程A必须睡眠等待,导致优先级高的进程A等待优先级低的进程C。
如果存在进程B,优先级在进程C和进程A之间,那么情况更糟糕。假设进程C仍然持有互斥锁,进程A正在等待。
进程B开始运行,因为它的优先级比进程C高,所以它可以抢占进程C,导致进程C持有互斥锁的时间延长,进程A等待的时间延长。
优先级继承(priority inheritance)可以解决优先级反转问题
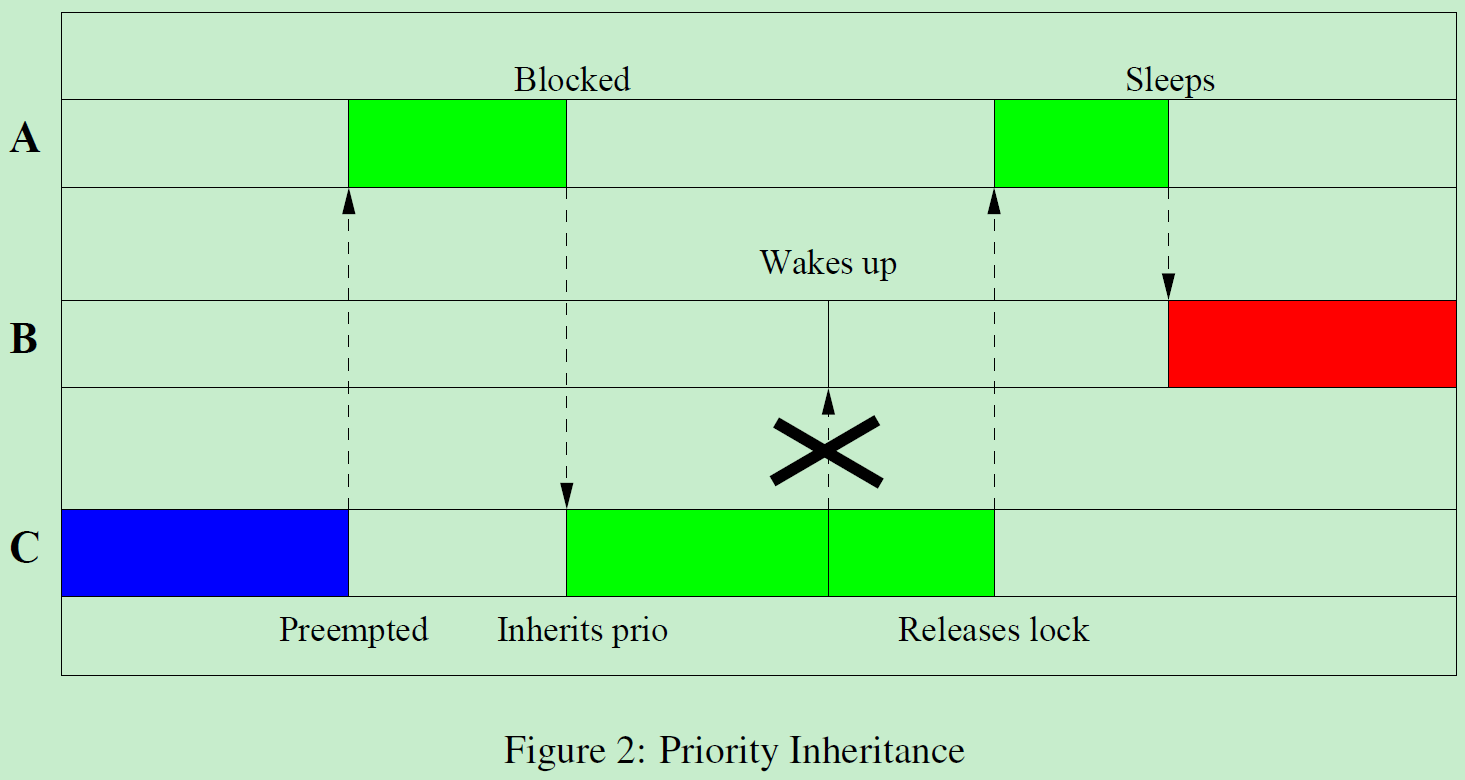
如果低优先级的进程持有互斥锁,高优先级的进程申请互斥锁,那么把持有互斥锁的进程的优先级临时提升到申请互斥锁的进程的优先级。
在上面的例子中,把进程C的优先级临时提升到进程A的优先级,防止进程B抢占进程C,使进程C尽快执行完临界区,减少进程A的等待时间
锁的等待者按优先级从高到低排序,如果优先级相等,那么先申请锁的进程的优先级高。
持有锁的进程,如果它的优先级比优先级最高的等待者低,那么把它的优先级临时提升到优先级最高的等待者的优先级。
如果普通进程持有锁,实时进程等待锁,那么把普通进程的优先级临时提升到实时进程的优先级,普通进程变成实时进程。
实时内核使用实时互斥锁实现互斥锁(mutex)和伤害/等待互斥锁(ww_mutex),支持优先级继承
rt_mutex_lock
__rt_mutex_lock
rt_mutex_lock_state
__rt_mutex_lock_state
rt_mutex_fastlock
rt_mutex_slowlock
rt_mutex_slowlock_locked
task_blocks_on_rt_mutex
task_blocks_on_rt_mutex
rt_mutex_adjust_prio(owner)
rt_mutex_setprio(p, pi_task);
p->sched_class = &fair_sched_class;
check_class_changed(rq, p, prev_class, oldprio);
p->sched_class->switched_to(rq, p);
对自旋锁的修改
自旋锁(spinlock_t)保护的临界区是不可抢占的,导致实时进程不能被及时调度。
实时内核使用互斥锁实现自旋锁(spinlock_t),临界区是可以抢占的,支持优先级继承(就可以避免优先级反转问题)。
在实时内核中,spin_lock_irq和spin_lock_irqsave不会禁止硬中断。
少数使用自旋锁保护的临界区不允许抢占,内核定义了原始自旋锁(raw_spinlock),提供传统的自旋锁。
在非实时内核中,spinlock和raw_spinlock完全相同。
选择spinlock和raw_spinlock的时候,最好坚持3个原则:
- 尽可能使用spinlock
- 绝对不允许被抢占和睡眠的地方,使用raw_spinlock,否则使用spinlock
- 如果临界区足够小,那么使用raw_spinlock。
#ifndef CONFIG_PREEMPT_RT
/* Non PREEMPT_RT kernels map spinlock to raw_spinlock */
typedef struct spinlock {
union {
struct raw_spinlock rlock;
};
...
} spinlock_t;
#else /* !CONFIG_PREEMPT_RT */
/* PREEMPT_RT kernels map spinlock to rt_mutex */
#include <linux/rtmutex.h>
typedef struct spinlock {
struct rt_mutex_base lock;
...
} spinlock_t;
#endif
对读写锁的修改
读写锁(rwlock_t)保护的临界区是不可抢占的,导致实时进程不能被及时调度
实时内核使用实时互斥锁实现读写锁,临界区是可以抢占的,支持优先级继承
read_lock_irq()、read_lock_irqsave()、write_lock_irq()和write_lock_irqsave()不会禁止硬中断
为了降低实现的复杂性,只允许一个进程获取读锁,进程可以递归获取读锁
#ifndef CONFIG_PREEMPT_RT
/*
* generic rwlock type definitions and initializers
*
* portions Copyright 2005, Red Hat, Inc., Ingo Molnar
* Released under the General Public License (GPL).
*/
typedef struct {
arch_rwlock_t raw_lock;
...
} rwlock_t;
#else /* !CONFIG_PREEMPT_RT */
#include <linux/rwbase_rt.h>
typedef struct {
struct rwbase_rt rwbase;
atomic_t readers;
...
} rwlock_t;
#endif
实时内核中,信号量也一样基于互斥锁,支持优先级继承
#ifndef CONFIG_PREEMPT_RT
struct rw_semaphore {
atomic_long_t count;
/*
* Write owner or one of the read owners as well flags regarding
* the current state of the rwsem. Can be used as a speculative
* check to see if the write owner is running on the cpu.
*/
atomic_long_t owner;
...
};
#else /* !CONFIG_PREEMPT_RT */
struct rw_semaphore {
struct rwbase_rt rwbase;
...
};
针对禁止内核抢占或硬中断保护的临界区的修改
对于使用 禁止硬中断 保护的临界区,因为在实时内核中使用内核线程执行大多数处理函数,所以大多数临界区不需要禁止硬中断
对于使用 禁止内核抢占 保护的临界区,在实时内核中大多数临界区可以修改为可以抢占的
为了在实时内核中把这两种临界区修改为可以抢占的,实时内核从3.0版本开始引入local_irq_lock
在合并到内核主线5.8版本的时候把名称改为local_lock(本地锁)。
local_lock为使用禁止内核抢占或硬中断保护的临界区提供了命名的作用域
非实时内核把local_lock映射到禁止内核抢占和禁止硬中断,如下:
- local_lock(&llock) 映射到 preempt_disable()
- local_unlock(&llock) 映射到 preempt_enable()
- local_lock_irq(&llock) 映射到 local_irq_disable()
- local_unlock_irq(&llock) 映射到 local_irq_enable()
- local_lock_irqsave(&llock) 映射到 local_irq_save()
- local_unlock_irqrestore(&llock) 映射到 local_irq_restore()
实时内核把local_lock映射到一个每处理器自旋锁。函数local_lock()用来获取一个每处理器本地锁
内核中禁止内核抢占或禁止硬中断的临界区比较多,需要判断是否可以使用local_lock替换,修改的工作量巨大,目前只有少数临界区使用local_lock
针对禁止软中断保护的临界区的修改
在实时内核中,软中断由软中断线程执行,或者在进程开启软中断的时候执行
使用禁止软中断保护的临界区 和 软中断线程 使用本地锁 softirq_ctrl.lock 互斥(5.4没有该实现,更高版本才有)
5.4上用的是 static DEFINE_LOCAL_IRQ_LOCK(bh_lock);
__local_bh_enable
__local_bh_enable_ip
__local_bh_disable_ip
实时内核开发注意事项
-
实时内核打开了配置项 CONFIG_IRQ_FORCED_THREADING=y 强制irq线程化
驱动确实需要关中断实现,禁止线程化,可以在注册中断时传递 IRQF_NO_THREAD flag标记 - 实时应用需要调用mlockall锁定内存,尽量避免page faults
进程启动初始化时提前分配好所有资源(stack_grow函数在堆栈上分配足够的空间,并且主动清零,强制提交内存到系统,避免后续发生page faults)
如果需要,提前调高系统默认的内存限额 RLIMIT_MEMLOCK#define MAX_STACK (512*1024) static void stack_grow (void) { char dummy[MAX_STACK]; memset(dummy, 0, MAX_STACK); return; } int main(int argc, char* argv[]) { [...] stack_grow (); // 在栈上分配空间,并且清零,强制提交到内存 mlockall(MCL_CURRENT | MCL_FUTURE); // 确保当前和未来要用的内存锁定 [...]禁用overcommit
echo 0 > /proc/sys/vm/overcommit_memory - 系统配置
# cat /proc/sys/kernel/sched_rt_period_us 1000000 # cat /proc/sys/kernel/sched_rt_runtime_us 950000sched_rt_period_us 每个可运行的进程都应该至少运行一次的某个时间间隔,包括实时和普通进程。
sched_rt_runtime_us 所有实时进程运行时间之和不超过该值,避免饿死低优先级进程。默认950ms,剩下的50ms留给普通进程。
如果实时进程运行超过950ms,就会被调度出去。
也就是说,采用这种默认配置,一直占用cpu的实时进程会每隔950毫秒就打个嗝,有50ms的时间是不能得到运行的
实时进程可能受不了这个,需要关闭的话,就得自己负责必要时让出cpu避免系统卡死,关闭命令如下# echo -1 > /proc/sys/kernel/sched_rt_runtime_us //禁用 sched_rt_runtime_us产生的功效 -
针对spinlock_t,spin_lock_irqsave并不会禁止硬件中断
少数使用自旋锁保护的临界区不允许抢占,内核定义了原始自旋锁(raw_spinlock),提供传统的自旋锁
禁中断或者禁抢占的场合再使用spin_lock就不合法了,必须使用raw spinlock
慎用raw_xxx 系列元语。只有很少的场合需要使用raw_xxx,比如调度器,架构相关代码以及RCU -
dot.config debug配置项能关闭尽量关闭,因为有可能带来不可预知的延迟
-
应用log记录一般会保存到存储介质,IO太频繁可能带来未知延迟
-
用户态实时进程如果有依赖中断和软中断,那么三者之间的优先级需要妥善配置。
软中断和用户实时进程,谁的优先级应该更高一些,可能需要结合实际业务逻辑,具体谁比谁设置优先级更高,得采取不同的策略,
(为了降低延迟,中断线程的优先级至少大于等于进程优先级) -
实时进程在下一次deadline到来之前没事做的时候,如果等待时长超过两倍的调度延迟时间,可以采用短暂忙等加sleep的方式
最好是sleep一段时间,然后提前唤醒,再busy wait一小段等时间 -
printk目前是rtpatch合入主线最大的障碍,printk的延迟在rt上是不可接受的
最后一个执行printk的进程会冲刷缓冲区,低优先级的进程可能因为大量打印阻塞高优先级进程
当前可以通过调低loglevel规避这个问题 -
高精度定时器
驱动如使用高精度定时器,需根据需要适配修改MODE
版本5.4为内核主线将来支持软实时做准备,增加HRTIMER_MODE_HARD,如下:
如果把到期模式指定为HRTIMER_MODE_HARD,那么在硬中断里面执行定时器回调函数,即使在实时内核中也是这样做。
如果没有指定到期模式,那么在非实时内核中默认使用硬中断到期模式,在实时内核中默认使用软中断到期模式。 - C库需要重新实现线程,支持优先级继承futex和时间处理
Glibc版本不低于2.5
当前uclibc实现不支持实时应用,不支持优先级继承的pthread mutex
安装实时补丁
选择一个内核版本和相应的实时补丁版本
cd ~/kernels
wget https://www.kernel.org/pub/linux/kernel/v5.x/linux-5.4.170.tar.xz
tar -jxf linux-5.4.170.tar.xz
mv linux-5.4.170 linux-5.4.170-rt68
cd linux-5.4.170-rt68
wget https://mirrors.edge.kernel.org/pub/linux/kernel/projects/rt/5.4/older/patch-5.4.170-rt68.patch.xz
unxz patch-5.4.170-rt68.patch.xz
patch -p1 < patch-5.4.170-rt68.patch
遇到的几个问题
记录下项目中应用 preempt-rt 时遇到的几个问题(版本号5.4.74-rt42)。
执行kdb bt命令没有打印调用栈
这个现象和RT补丁的printk ringbuffer实现有关系,为了降低printk可能带来的不可预知的延迟, 目前printk_kthread_func刷到串口的操作是放到了printk的内核线程里,只有有新的打印数据的时候才会唤醒printk内核线程
kdb_bt1
-> kdb_show_stack
-> show_stack
-> dump_backtrace
-> printk
-> vprintk_func
-> vprintk_emit
-> prb_commit(提交到ringbuffer)
-> wake_up_interruptible_all(rb->wq); // 唤醒printk内核线程刷到串口
上面的调用栈只是暂时写入了ringbuffer,然后事件通知printk内核线程需要刷新缓冲区,而没有立即调用c->write 刷到串口
但是也可以在执行完bt之后紧接着执行dmesg,从而可以主动从缓冲区读出来
打印的时候可以直接调用kdb模块自己的kdb_printf接口,这个接口有主动调用console->write,可以立即把栈刷出来
但是需要在内核添加kdb版本的show_stack 和 dump_backtrace,里面用kdb_printf替换printk
修改后可以立即把调用栈刷新出来
$ echo g > /proc/sysrq-trigger
Entering kdb (current=0xffff0001f4d49e80, pid 141) on processor 0 due to Keyboard Entry
[0]kdb> bt
Stack traceback for pid 141
0xffff0001f4d49e80 141 1 1 0 R 0xffff0001f4d4a970 *ash
[0]kdb> dmesg 100
[ 10.458705] 000: sysrq: DEBUG
[ 11.692792] 000: Call trace:
[ 11.692809] 000: dump_backtrace+0x0/0x150
[ 11.693576] 000: show_stack+0x24/0x30
[ 11.693591] 000: kdb_show_stack+0x68/0xf8
[ 11.693602] 000: kdb_bt1.isra.1+0x100/0x140
[ 11.693608] 000: kdb_bt+0x330/0x428
[ 11.693615] 000: kdb_parse+0x390/0x738
[ 11.693621] 000: kdb_main_loop+0x40c/0x8e8
[ 11.693627] 000: kdb_stub+0x258/0x460
[ 11.693633] 000: kgdb_cpu_enter+0x340/0x800
[ 11.693640] 000: kgdb_handle_exception+0x1c8/0x240
[ 11.693646] 000: kgdb_compiled_brk_fn+0x34/0x48
[ 11.693654] 000: call_break_hook+0x84/0xa0
[ 11.693662] 000: brk_handler+0x28/0x68
[ 11.693669] 000: do_debug_exception+0xa4/0x168
[ 11.693674] 000: el1_dbg+0x18/0x8c
[ 11.693679] 000: kgdb_breakpoint+0x44/0x88
[ 11.693685] 000: sysrq_handle_dbg+0x2c/0x60
[ 11.693691] 000: __handle_sysrq+0xb4/0x1a0
[ 11.693700] 000: write_sysrq_trigger+0x98/0xb8
[ 11.693706] 000: proc_reg_write+0x90/0xe0
[ 11.693716] 000: __vfs_write+0x48/0x80
[ 11.693724] 000: vfs_write+0xb8/0x1d8
[ 11.693730] 000: ksys_write+0x74/0xf8
[ 11.693735] 000: __arm64_sys_write+0x24/0x30
[ 11.693742] 000: el0_svc_common.constprop.1+0x7c/0x1a8
[ 11.693748] 000: el0_svc_handler+0x34/0xa0
[ 11.693754] 000: el0_svc+0x8/0x204
MMC驱动代码触发死锁BUG
实时补丁打进去之后发现一个MMC死锁问题
这个中断申请的时候禁止线程化
devm_request_irq(&pdev->dev, mmc_irq[0], ccc_mmc_interrupt, IRQF_NO_THREAD, KBUILD_MODNAME, host);
worker线程执行mmc work调度到的mmc_blk_rw_wait时候准备把自己挂到等待队列
刚拿到队列锁mq->wait->lock,就被中断(ccc_mmc_interrupt)打断
中断函数里也要拿这个队列锁唤醒等待任务,因为是同一把队列锁,触发内核检测BUG
驱动代码调用devm_request_irq注册的时候提供了标记IRQF_NO_THREAD
这个中断是否必须禁止线程化,是否可以去掉该标记,需要考虑下这个中断handler和mmc work的互斥关系,解决当前死锁问题
1036 void __sched rt_spin_lock_slowlock_locked(struct rt_mutex *lock,
1037 struct rt_mutex_waiter *waiter,
1038 unsigned long flags)
1039 {
1040 struct task_struct *lock_owner, *self = current;
1041 struct rt_mutex_waiter *top_waiter;
1042 int ret;
1043
1044 if (__try_to_take_rt_mutex(lock, self, NULL, STEAL_LATERAL))
1045 return;
1046
1047 BUG_ON(rt_mutex_owner(lock) == self); //触发内核检测BUG
<4>[ 258.332208] 000: ------------[ cut here ]------------
<2>[ 258.332212] 000: kernel BUG at kernel/locking/rtmutex.c:1047!
<0>[ 258.332216] 000: Internal error: Oops - BUG: 0 [#1] PREEMPT_RT SMP
<4>[ 258.343748] 000: CPU: 0 PID: 3690 Comm: kworker/0:2H Tainted: G W 5.4.74-rt54 #1
<4>[ 258.343752] 000: Hardware name: Marvell OcteonTX CN96XX board (DT)
<4>[ 258.343759] 000: Workqueue: kblockd blk_mq_run_work_fn
<4>[ 258.343761] 000: pstate: 60400089 (nZCv daIf +PAN -UAO)
<4>[ 258.343763] 000: pc : rt_spin_lock_slowlock_locked+0x25c/0x290
<4>[ 258.343767] 000: lr : rt_spin_lock_slowlock_locked+0x3c/0x290
<4>[ 258.343771] 000: sp : ffff80001000fc10
<4>[ 258.343773] 000: x29: ffff80001000fc10 x28: 0000000000000000
<4>[ 258.343778] 000: x27: 0000000000000080 x26: ffff000015aee200
<4>[ 258.343782] 000: x25: ffff800011630018 x24: ffff800011a67988
<4>[ 258.343785] 000: x23: 0000000000000003 x22: ffff80001000fca8
<4>[ 258.343790] 000: x21: ffff000011df8380 x20: ffff80001000fca8
<4>[ 258.343793] 000: x19: ffff000016d2c918 x18: 0000000000000000
<4>[ 258.343797] 000: x17: 0000000000000000 x16: 0000000000000000
<4>[ 258.343801] 000: x15: 0000000000000000 x14: 0000000000000000
<4>[ 258.343805] 000: x13: 0000000000000000 x12: 0000000000000000
<4>[ 258.343809] 000: x11: 0000000000000000 x10: 0000000000000040
<4>[ 258.343812] 000: x9 : ffff800010f1b204 x8 : 0000000000004000
<4>[ 258.343817] 000: x7 : ffff000016a88678 x6 : ffff000011df8380
<4>[ 258.343820] 000: x5 : ffff000016d2c930 x4 : ffff000011df8380
<4>[ 258.343825] 000: x3 : 0000000000000001 x2 : ffff000011df8381
<4>[ 258.343828] 000: x1 : ffff000011df8380 x0 : ffff000011df8380
<4>[ 258.343832] 000: Call trace:
<4>[ 258.343834] 000: rt_spin_lock_slowlock_locked+0x25c/0x290
<4>[ 258.343838] 000: rt_spin_lock_slowlock+0x64/0x98
<4>[ 258.343841] 000: rt_spin_lock+0x78/0x80
<4>[ 258.343843] 000: __wake_up_common_lock+0x60/0xb8
<4>[ 258.343847] 000: __wake_up+0x1c/0x28
<4>[ 258.343850] 000: mmc_blk_mq_req_done+0x198/0x1d8
<4>[ 258.343852] 000: ccc_mmc_interrupt+0x1ec/0x618
<4>[ 258.343855] 000: __handle_irq_event_percpu+0x78/0x2f0
<4>[ 258.343858] 000: handle_irq_event_percpu+0x68/0xb8
<4>[ 258.343861] 000: handle_irq_event+0x7c/0x128
<4>[ 258.343864] 000: handle_fasteoi_irq+0xcc/0x1b0
<4>[ 258.343867] 000: generic_handle_irq+0x2c/0x40
<4>[ 258.343870] 000: __handle_domain_irq+0x98/0x108
<4>[ 258.343872] 000: gic_handle_irq+0x8c/0x1bc
<4>[ 258.343875] 000: el1_irq+0xbc/0x180
<4>[ 258.343877] 000: rt_spin_lock+0x58/0x80
<4>[ 258.343880] 000: prepare_to_wait_event+0x3c/0x108
<4>[ 258.343883] 000: mmc_blk_rw_wait+0xe0/0x140
<4>[ 258.343886] 000: mmc_blk_mq_issue_rq+0x328/0x7fc
<4>[ 258.343888] 000: mmc_mq_queue_rq+0x10c/0x278
<4>[ 258.343891] 000: blk_mq_dispatch_rq_list+0xb0/0x5d8
<4>[ 258.343894] 000: blk_mq_do_dispatch_sched+0x70/0x110
<4>[ 258.343897] 000: blk_mq_sched_dispatch_requests+0x138/0x1e0
<4>[ 258.343900] 000: __blk_mq_run_hw_queue+0xb4/0x128
<4>[ 258.343903] 000: blk_mq_run_work_fn+0x24/0x30
<4>[ 258.343906] 000: process_one_work+0x1ec/0x4d8
<4>[ 258.343909] 000: worker_thread+0x48/0x480
<4>[ 258.343913] 000: kthread+0x158/0x168
<4>[ 258.343916] 000: ret_from_fork+0x10/0x18
ftrace调整buffer size时挂住
# echo 40960 > /sys/kernel/debug/tracing/buffer_size_kb // echo时bash进程挂住
Kdb> bt
0xffff0001c50e3e00 2390 2389 0 0 D 0xffff0001c50e4930 bash // echo bash任务D状态挂死了
Call trace:
__switch_to+0xa4/0x1f0
__schedule+0x24c/0x6a8
schedule+0x40/0xe0
schedule_timeout+0x2cc/0x3e0
wait_for_completion+0x84/0x110
ring_buffer_resize+0x40c/0x480
__tracing_resize_ring_buffer+0x3c/0x130
tracing_entries_write+0xd0/0x178
__vfs_write+0x20/0x48
vfs_write+0xb8/0x1d8
ksys_write+0x6c/0xf0
__arm64_sys_write+0x20/0x28
el0_svc_handler+0xb4/0x1f0
el0_svc+0x8/0x1e4
- 因为ring buffer是percpu的,调整buffer size每个核都需要调整自己的缓冲区大小
ring_buffer_resize 1833 cpu_buffer->nr_pages_to_update = 0; 1834 } else { 1835 if (!update_if_isolated(cpu_buffer, cpu)) 1836 schedule_work_on(cpu, 1837 &cpu_buffer->update_pages_work); // 依赖于percpu system workqueue 1838 } 1839 } 1840 1841 /* wait for all the updates to complete */ 每个核的buffer都要调整 1842 for_each_buffer_cpu(buffer, cpu) { 1843 cpu_buffer = buffer->buffers[cpu]; 1844 if (!cpu_buffer->nr_pages_to_update) // /* ring buffer pages to update, > 0 to add, < 0 to remove */ 1845 continue; 1846 1847 if (cpu_online(cpu)) 1848 wait_for_completion(&cpu_buffer->update_done); // 挂在这里了,等待每个核都调整完成后,收到通知才能返回 1849 cpu_buffer->nr_pages_to_update = 0; 1850 } 1851 1852 put_online_cpus(); -
这个任务是由percpu system workqueue负责处理的,每个cpu都要执行对应的work
响应echo的内核态处理函数需要等待其它核work都执行完毕,收到完成量通知才能返回,当前就是挂在等待完成量通知 -
设备一共6个cpu,除了0核,1-5核每个核都绑定了一个实时进程,并且业务逻辑是始终占据cpu不释放
所以猜测是1-5核cpu被实时进程完全占据,system workqueue 得不到调度机会,导致调整buffersize 的work不能执行
然后Echo就挂在了等待完成量通知的位置 - 设备上rt proc相关配置如下
# cat /proc/sys/kernel/sched_rt_period_us 1000000 // 1000000 us == 1s # cat /proc/sys/kernel/sched_rt_runtime_us -1 // -1表示 如果实时进程如果不主动释放cpu,那么可以完全占据cpu不释放;在设备上配置为-1,是希望1-5核心上实时进程始终占据cpu - 手动调整RT调度器策略,强制每1s都让出50ms给非实时进程,设置之后,之前D状态的bash进程返回,buffer resize配置成功
# echo 950000 > /proc/sys/kernel/sched_rt_runtime_us - 所以如果想利用ftrace接口,可以临时改为95000,修改buffer size 成功之后再改回去,改成-1,这样可以消除该问题
这个只能说是业务逻辑和内核代码逻辑产生冲突
ping丢包和ifconfig挂死
这个问题和ftrace调整buffer size时挂住问题 一样,都是实时任务占据cpu导致的。这里不再多说,只记录一下现象和解决办法。
设备内部集成有两个同一厂商但是不同cpu型号的SoC,二者通过内部局域网通信。
根据业务需求,各自有各自的任务,各自跑各自的系统,只不过用的同一个实时内核镜像。
现在从A ping B ping包有丢包,在B 上执行ifconfig命令会D状态卡住。
B上共6个核,丢包和ifconfig命令都是因为有中断线程绑定到了1-5核(0核跑杂七杂八的任务)。
而1-5核上各自跑着一个优先级为99的用户态实时业务进程,高于中断线程优先级,而中断线程是网卡驱动注册的,
这就导致tx传输被阻塞,进而又阻塞了tx_timeout worker线程,worker线程拿着rtnl-lock,所以又致使执行ifconfig时会阻塞在rtnl_lock
所以要么提高中断线程的优先级,要么把这几个线程迁移到0核
hrtimer事件丢失
一开始是注意到执行top命令的时候,过不了多久top就不再定时刷新数据了,Ctrl+C也没反应,挂住不动了
查看top进程并没有D状态挂死,只是一直处于休眠状态,得不到调度
正常情况下top每隔三秒刷新串口输出,从下面的调用栈可以看出在内核态是利用hrtimer驱动定时器刷新的
出现问题时,一直没有hrtimer软中断报上来,所以top定时器回调得不到调度,表现为控制台输出不刷新
cat /proc/softirqs 也可以明显看到HRTIMER统计数据始终保持不变
[root@(none) /]# ps aux | grep top
root 2397 1.1 0.0 11456 6976 ttyp1 S+ 11:59 1:18 /usr/bin/top -H
root 2400 0.0 0.0 4288 2176 ? S 13:51 0:00 grep --color=auto top
[root@(none) /]# cat /proc/2397/stack
[<0>] __switch_to+0xa4/0x1f0
[<0>] do_select+0x3c0/0x560
[<0>] core_sys_select+0x344/0x4d8
[<0>] __arm64_sys_pselect6+0x188/0x2e8
[<0>] el0_svc_handler+0xb4/0x1f0
[<0>] el0_svc+0x8/0x1e4
[root@(none) /]#
[root@(none) /]#
Entering kdb (current=0xffff0001c6ddaa80, pid 1980) on processor 0 due to Keyboard Entry
[0]kdb> btp 2397
Stack traceback for pid 2397
0xffff0001cd2e5d00 2397 2377 0 0 S 0xffff0001cd2e6830 top
Call trace:
__switch_to+0xa4/0x1f0
__schedule+0x24c/0x6a8
schedule+0x40/0xe0
schedule_hrtimeout_range_clock+0x9c/0x1e0 // Line 2191 of "kernel/time/hrtimer.c"
schedule_hrtimeout_range+0x18/0x20
do_select+0x3c0/0x560
core_sys_select+0x344/0x4d8
__arm64_sys_pselect6+0x188/0x2e8
el0_svc_handler+0xb4/0x1f0
el0_svc+0x8/0x1e4
2161 int __sched
2162 schedule_hrtimeout_range_clock(ktime_t *expires, u64 delta,
2163 const enum hrtimer_mode mode, clockid_t clock_id)
2164 {
2165 struct hrtimer_sleeper t;
......
2183
2184 hrtimer_init_sleeper_on_stack(&t, clock_id, mode);
2185 hrtimer_set_expires_range_ns(&t.timer, *expires, delta);
2186 hrtimer_sleeper_start_expires(&t, mode);
2187
2188 if (likely(t.task))
2189 schedule(); // 进程挂在这里,始终没有返回
2190
2191 hrtimer_cancel(&t.timer);
2192 destroy_hrtimer_on_stack(&t.timer);
2193
2194 __set_current_state(TASK_RUNNING);
2195
2196 return !t.task ? 0 : -EINTR;
2197 }
我们知道,softirq需要先raise,先设置percpu标记HRTIMER_SOFTIRQ
这样下次softirqd线程run_ksoftirqd执行的时候会调用相应的软中断处理函数
如果没有raise操作,下次run_ksoftirqd不会调用到回调 action
所以加了两处调试打印,一处是raise的地方,一处是__do_softirq里面
抓到的打印信息显示,最后一次置位HRTIMER_SOFTIRQ标记之后
__do_softirq中遍历__softirq_pending位时,HRTIMER_SOFTIRQ标记位丢失,没能调用到回调hrtimer_run_softirq
hrtimer_run_softirq ---> hrtimer_update_softirq_timer 没能续命, 一口气吊不上来,后续所有hrtimer softirq事件全部丢失
hrtimer_interrupt
1805 if (!ktime_before(now, cpu_base->softirq_expires_next)) {
1806 cpu_base->softirq_expires_next = KTIME_MAX;
1807 cpu_base->softirq_activated = 1;
1808 raise_softirq_irqoff(HRTIMER_SOFTIRQ); // 这里添加调试打印
1809 }
__do_softirq
559 while ((softirq_bit = ffs(pending))) { // 循环里添加调试打印
560 unsigned int vec_nr;
561 int prev_count;
562
563 h += softirq_bit - 1;
564
565 vec_nr = h - softirq_vec;
566 prev_count = preempt_count();
567
568 kstat_incr_softirqs_this_cpu(vec_nr);
569
570 trace_softirq_entry(vec_nr);
571 h->action(h);
572 trace_softirq_exit(vec_nr);
573 if (unlikely(prev_count != preempt_count())) {
574 pr_err("huh, entered softirq %u %s %p with preempt_count %08x, exited with %08x?\n",
575 vec_nr, softirq_to_name[vec_nr], h->action,
576 prev_count, preempt_count());
577 preempt_count_set(prev_count);
578 }
579 h++;
580 pending >>= softirq_bit;
581 }
RT补丁又提高了并发程度,所以就怀疑 HRTIMER_SOFTIRQ 可能因为代码并发有问题被冲掉了
pending标记是个percpu变量,很可能是当前cpu上可能其它流程raise softirq时冲掉了标记位
就在置位的必经之路 __raise_softirq_irqoff 里面加了个 trace_dump_stack,抓到如下调用栈
irq/237-eth1-rx-2042 [000] .....12 70.122246: <stack trace> // . 标记处于中断使能上下文
=> __raise_softirq_irqoff
=> __napi_schedule_irqoff // 该接口本身不会关中断,但是要求所处上下文关中断
=> cq_intr_handler // 驱动注册的中断handler
=> irq_forced_thread_fn
=> irq_thread
=> kthread
=> ret_from_fork
无论是否打了实时补丁 hrtimer_interrupt 本身都是硬中断上下文
实时补丁打进来之后,驱动中断处理函数cq_intr_handler从中断上下文变成了线程上下文,原本关中断的上下文,现在开了中断
cq_open // 网络收发包驱动代码
1641 err = request_irq(pci_irq_vector(pf->pdev, vec),
1642 cq_intr_handler, 0, irq_name, // 这里注册了handler
1643 &qset->napi[qidx]);
net/core/dev.c
3881 /* Called with irq disabled */
3882 static inline void ____napi_schedule(struct softnet_data *sd,
3883 struct napi_struct *napi)
3884 {
3885 list_add_tail(&napi->poll_list, &sd->poll_list);
3886 __raise_softirq_irqoff(NET_RX_SOFTIRQ);
3887 }
hrtimer_interrupt函数里也会调用raise_softirq_irqoff,设置HRTIMER_SOFTIRQ标记
出现问题时是 hrtimer_interrupt 中断了 cq_intr_handler
中断返回之后 cq_intr_handler ->… -> __raise_softirq_irqoff 恢复执行的时候
把 hrtimer_interrupt 设置的 HRTIMER_SOFTIRQ 标记位冲掉了,导致后续所有 hrtimer softirq 事件全部丢失
top不刷新只是其中一种现象,还会引起其它问题,毕竟hrtimer softirq完全失效了
使用关中断接口 napi_schedule 即可解决该问题
Index: drivers/net/cq/nic/cq_pf.c
==================================================================
--- drivers/net/cq/nic/cq_pf.c (revision 44406)
+++ drivers/net/cq/nic/cq_pf.c (working copy)
int qidx = cq_poll->cint_idx;
+ unsigned long flags;
/* Disable interrupts.
*
@@ -1272,7 +1273,7 @@
ooo_write64(pf, NIX_LF_CINTX_ENA_W1C(qidx), BIT_ULL(0));
/* Schedule NAPI */
- napi_schedule_irqoff(&cq_poll->napi);
+ napi_schedule(&cq_poll->napi);
return IRQ_HANDLED;
}
irqaffinity 中断亲和性不生效
产品属于5G设备,为了尽最大可能降低延迟,给实时进程分配了单独的cpu
同时迁移irqs和kernel threads,给内核传参 isolcpus=1-5 nohz_full=1-5 irqaffinity=0
但是产品同事反馈说内核传参irqaffinity=0绑定irqs到0核并没有生效,其他核还是有中断上来
先看下irqaffinity传参处理,入参cpu范围会设置到全局变量irq_default_affinity
static int __init irq_affinity_setup(char *str)
{
alloc_bootmem_cpumask_var(&irq_default_affinity);
cpulist_parse(str, irq_default_affinity);
/*
* Set at least the boot cpu. We don't want to end up with
* bugreports caused by random commandline masks
*/
cpumask_set_cpu(smp_processor_id(), irq_default_affinity); // 无论传参是哪些cpu,至少要把当前boot cpu设置到irq亲合性cpu列表里
return 1;
}
__setup("irqaffinity=", irq_affinity_setup); // 所以如果入参写成irqaffinity=0,那么等价于只指定一个boot cpu负责处理irqs
系统初始化使用全局变量irq_default_affinity记录到每个中断对应的desc
static void __init init_irq_default_affinity(void)
{
if (!cpumask_available(irq_default_affinity)) // 没有指定irqaffinity参数,则数值为空
zalloc_cpumask_var(&irq_default_affinity, GFP_NOWAIT);
if (cpumask_empty(irq_default_affinity))
cpumask_setall(irq_default_affinity); // 没指定,内容为空就默认所有cpu都可以处理irq
}
start_kernel
early_irq_init
init_irq_default_affinity // 初始化全局变量 irq_default_affinity,默认任何irq可以在所有cpu上处理
desc = alloc_desc(i, node, 0, NULL, NULL); // 为每个中断分配对应的desc
desc_set_defaults(irq, desc, node, affinity, owner);
desc_smp_init(desc, node, affinity); // 系统在desc里面跟踪记录亲和性,因为affinity为NULL,所以所有cpu均可处理
然后每个中断注册的时候会配置当前irq的亲和性,用的是desc里的affinity cpumask
irq亲和性最终是要下发给gic,这样相应中断上来的时候才会上报给指定cpu
request_threaded_irq
__setup_irq
irq_startup
irq_setup_affinity // 使用 irq_default_affinity全局变量
irq_do_set_affinity
chip->irq_set_affinity // msi_domain_set_affinity
parent->chip->irq_set_affinity(parent, mask, force); // its_set_affinity
its_send_movi(its_dev, target_col, id); // irq亲和性最终是要下发给gic ,这样相应中断上来的时候才会上报给指定cpu
在走读irq affinity相关代码的时候发现irq_do_set_affinity
该函数会直接调用chip->irq_set_affinity,其实就是msi_domain_set_affinity
msi_domain_set_affinity又调用了its_set_affinity
在irq_do_set_affinity和its_set_affinity加了调试打印,抓到下面的信息
把不同的事件ID映射给不同的cpu,这样中断就摊开了,达到负载均衡的效果
所以是网卡驱动结合业务逻辑考虑,内部实现强制分派irqs到各个cpu,所以就覆盖了参数irqaffinity的配置
这个问题留给产品去和厂家协商解决。
[ 39.623895] [its_set_affinity 1171] cpu 1, id 72
[ 39.780683] [its_set_affinity 1171] cpu 2, id 73
[ 39.937458] [its_set_affinity 1171] cpu 3, id 74
[ 40.094253] [its_set_affinity 1171] cpu 4, id 75
[ 40.251292] [its_set_affinity 1171] cpu 5, id 76
[ 48.709140] CPU: 0 PID: 1741 Comm: ifconfig Not tainted 5.4.74 #1
[ 48.715230] Hardware name: Marvell OcteonTX CNF95XX board (DT)
[ 48.721061] Call trace:
[ 48.723591] dump_backtrace+0x0/0x160
[ 48.727250] show_stack+0x1c/0x28
[ 48.730562] dump_stack+0xe8/0x168
[ 48.733962] msi_domain_set_affinity+0xcc/0x100
[ 48.738490] irq_do_set_affinity+0x64/0x118
[ 48.742671] irq_set_affinity_locked+0x104/0x160
[ 48.747285] __irq_set_affinity+0x7c/0x100
[ 48.751378] irq_set_affinity_hint+0x70/0xa0
[ 48.755646] otx2_set_cints_affinity+0xf8/0x210 // 网卡驱动代码初始化时强制设置亲和性,覆盖了irqaffinity配置,据厂商介绍说是为了负载均衡
[ 48.760173] otx2_open+0x4dc/0x870
[ 48.763572] __dev_open+0xdc/0x168
[ 48.766969] __dev_change_flags+0x16c/0x1d0
[ 48.771149] dev_change_flags+0x28/0x68
[ 48.774983] devinet_ioctl+0x3f0/0x750
[ 48.778729] inet_ioctl+0x1fc/0x378
[ 48.782213] sock_do_ioctl+0x50/0x2c8
[ 48.785872] sock_ioctl+0x3d8/0x500
[ 48.789358] do_vfs_ioctl+0xc0/0xb28
[ 48.792928] ksys_ioctl+0x80/0xb0
[ 48.796241] __arm64_sys_ioctl+0x24/0xd8
[ 48.800161] el0_svc_common.constprop.2+0x98/0x188
[ 48.804950] el0_svc_handler+0x28/0x88
[ 48.808696] el0_svc+0x8/0x22c
参考索引
https://docs.kernel.org/locking/rt-mutex-design.html
https://lwn.net/Articles/909980/
https://lwn.net/Articles/780556/
https://lwn.net/Articles/828477/
https://mp.weixin.qq.com/s/wViW90NyZ_CleP2YHIgHhg
https://docs.kernel.org/scheduler/sched-rt-group.html
https://www.linuxfoundation.org/blog/blog/intro-to-real-time-linux-for-embedded-developers
https://wiki.linuxfoundation.org/realtime/documentation/howto/debugging/debug-steps
《Challenges Using Linux as a Real-Time Operating System》