套接字缓冲区 sk_buff
套接字缓冲区,用于内核协议栈管理报文收发的结构体,在网络实现的各个层次之间交换数据,而无需来回复制分组数据,对性能提高很可观。
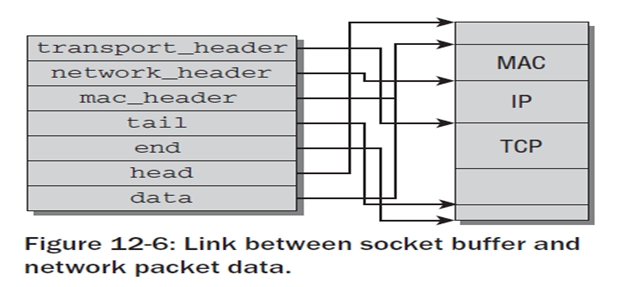
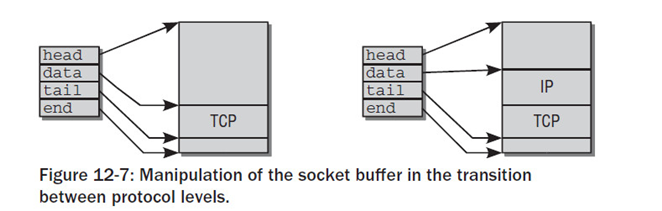
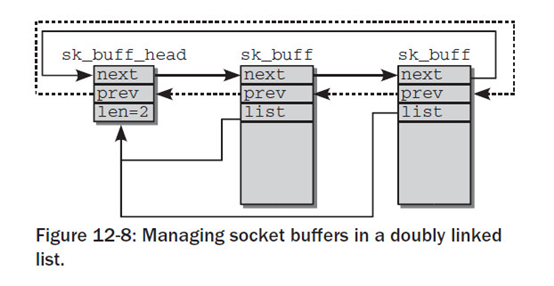
套接字缓冲区管理方式
struct sk_buff {
...
};
struct sk_buff_head {
/* These two members must be first to match sk_buff. */
struct_group_tagged(sk_buff_list, list,
struct sk_buff *next;
struct sk_buff *prev;
);
__u32 qlen;
spinlock_t lock;
};
分组发送
TX流程图
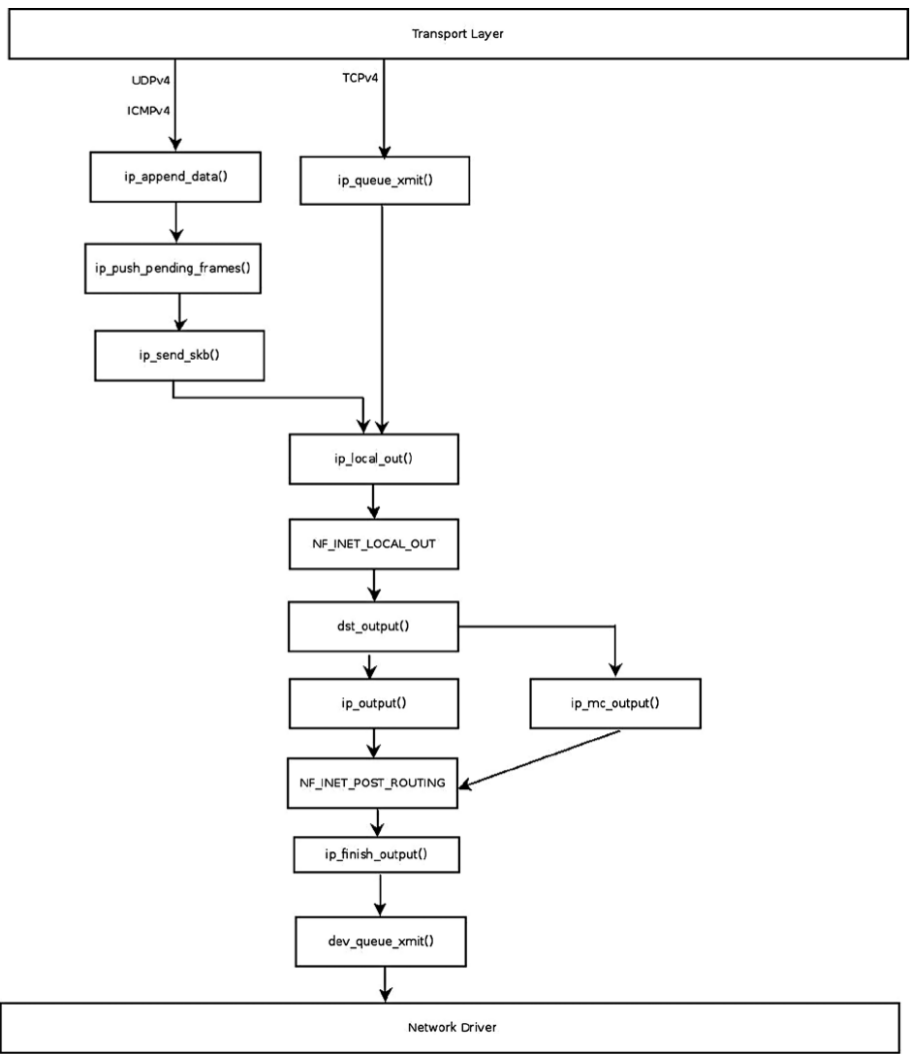
skb_buff发送操作
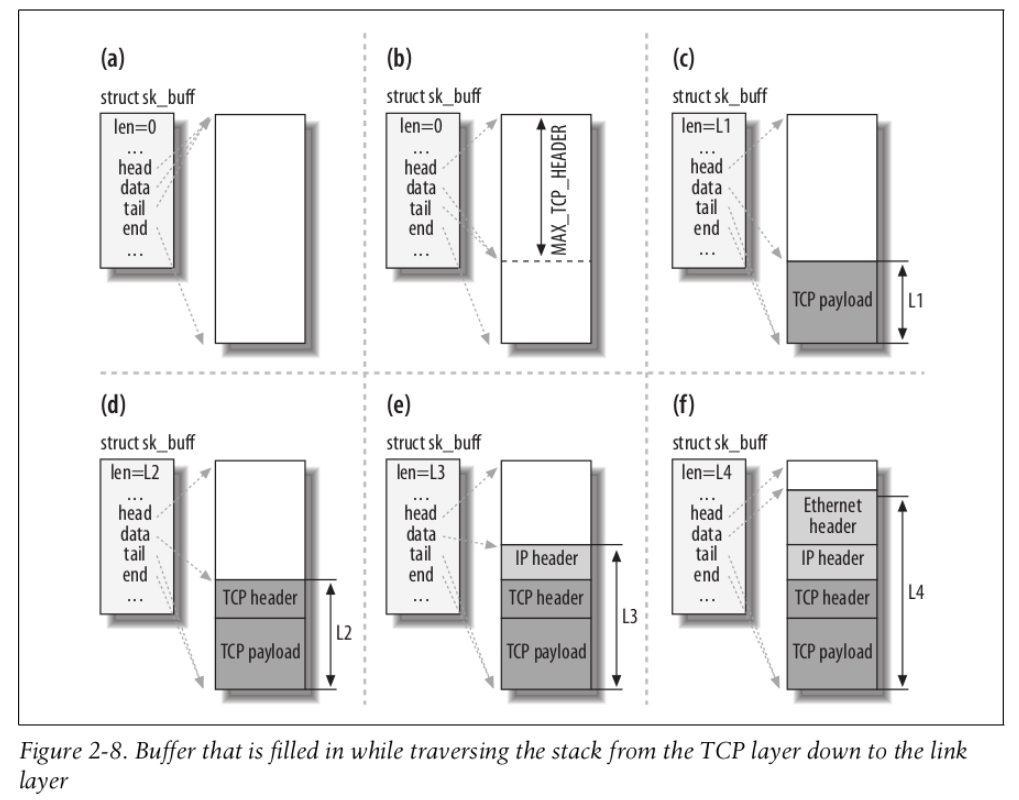
-
在一个新分组产生时,TCP层首先在用户空间中分配内存来容纳该分组数据(首部和净荷)。
分组的空间大于数据实际需要的长度,因此较低的协议层可以进一步增加首部。 -
分配一个套接字缓冲区sk_buff,使得head和end分别指向上述内存区的起始和结束地址,而TCP数据位于data和tail之间。
-
在套接字缓冲区传递到互联网络层时,必须增加一个新层。 只需要向已经分配但尚未占用的那部分内存空间写入数据即可,除了data之外的所有指针都不变,data现在指向IP首部的起始处。
下面的各层会重复同样的操作,直至分组完成,即将通过网络发送。
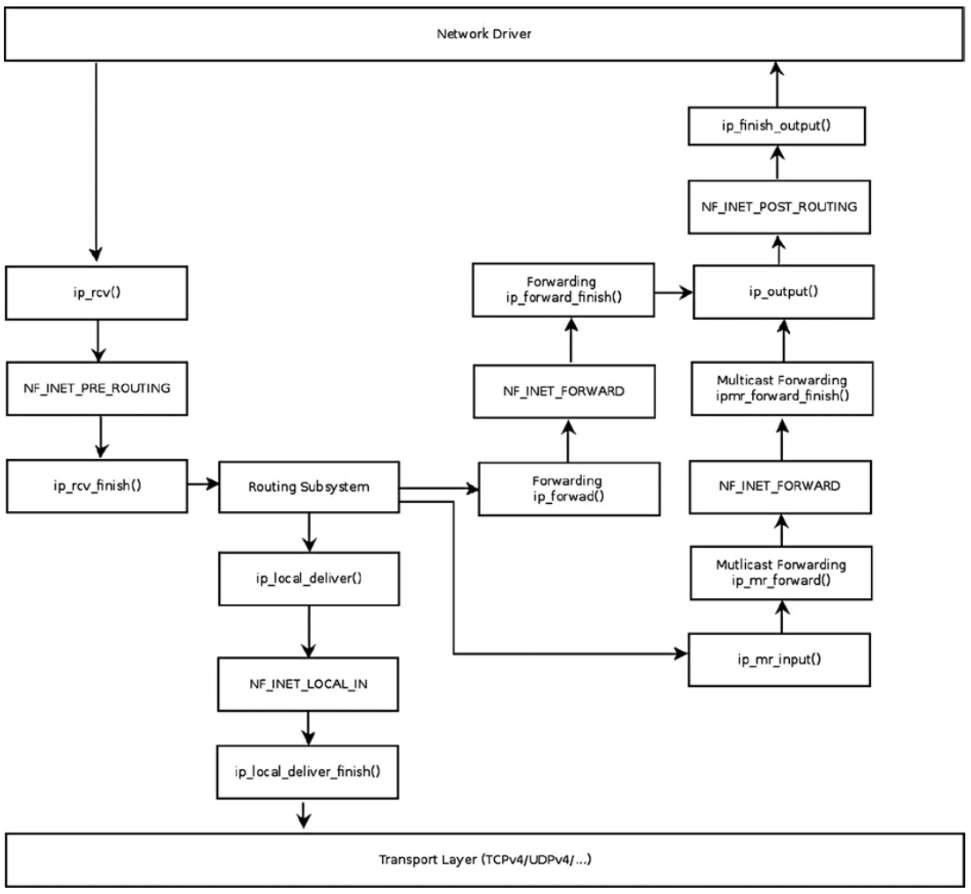
分组接收
RX流程图
为提高多处理器系统的性能,为每个CPU创建等待队列,支持分组的并行处理
/* Incoming packets are placed on per-CPU queues */
struct softnet_data {
struct list_head poll_list; // 入口队列中有新帧等待被处理的设备列表,此列表中的设备中断都处于关闭状态,
/* 非NAPI 设备才会使用这两个字段 */
struct sk_buff_head input_pkt_queue; //所有进入的分组链表
struct napi_struct backlog;
}
网卡驱动和协议栈交接
分组数据复制到内核分配的一个内存中,并在整个分析期间一直处于内存区中。
与该分组相关的套接字缓冲区在各层之间顺序传递,各层依次将其中的各个指针设置为正确的值。
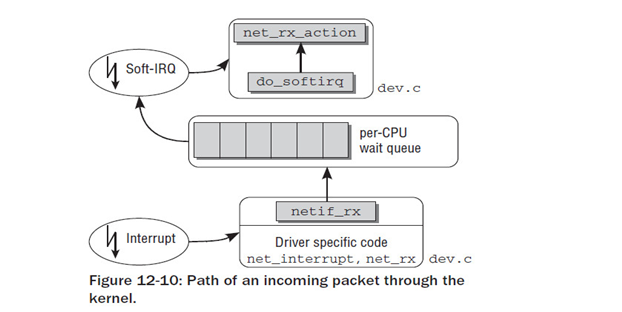
-
net_interrupt 是有驱动程序设置的中断处理程序。
它确定该中断是否真的是由接收到的分组引发的(也存在其它可能性,例如,报告错误或确认某些适配器执行的传输任务),
如果确实如此,则将控制转移到net_rx。 -
net_rx函数也是特定于网卡的,首先创建一个新的套接字缓冲区。
分组的内容接下来从网卡传输到缓冲区(也就是进入了物理内存),然后使用内核源代码中针对各种传输类型的库函数来分析首部数据。
这项分析将确定分组数据所使用的网络协议层,例如IP协议。 -
与上述两个方法不同,netif_rx函数不是特定于网络驱动程序的。调用该函数,标志着控制由特定于网卡的代码转移到了网络层的通用接口部分。
该函数将接收到的分组放置到一个特定于CPU的等待队列上,在结束工作之前将软中断NET_RX_SOFTIRQ标记为即将执行,然后退出中断上下文,使得CPU可以执行其它任务。 -
为提高多处理器系统的性能,对每个CPU都会创建等待队列,支持分组的并行处理。
-
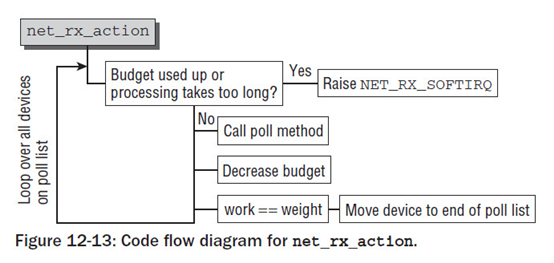
net_rx_action 作为软中断的处理函数
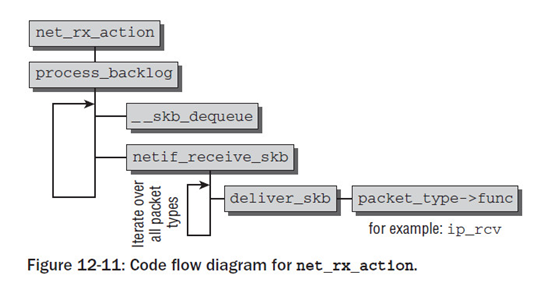
遍历sd->poll_list设备链表, 如果有需要处理的设备, 就调用网络设备驱动的poll方法,从网卡芯片接收报文
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
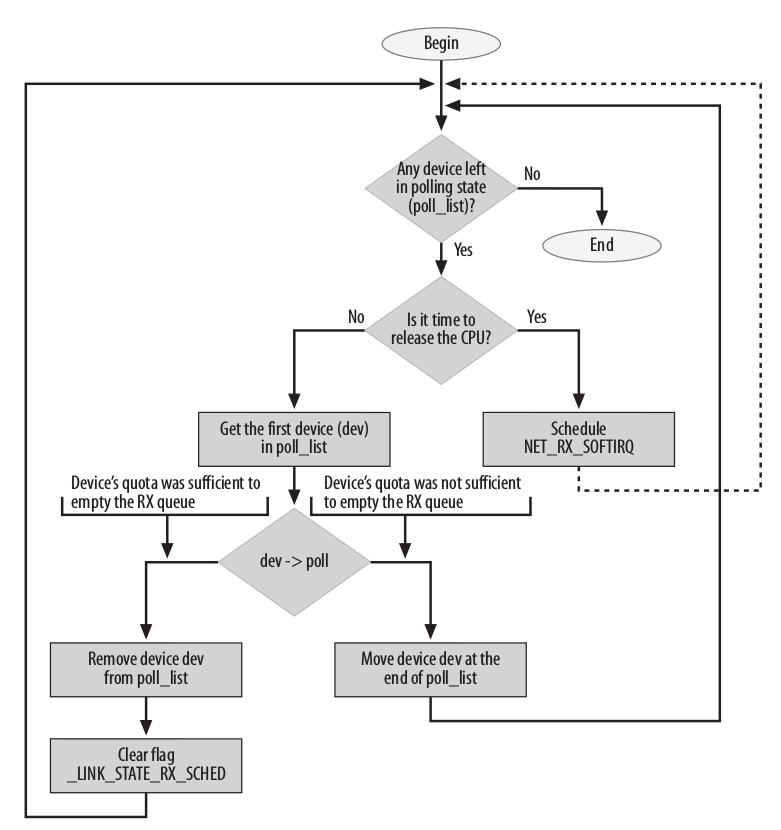
a. __skb_dequeue从等待队列移除一个套接字缓冲区,该缓冲区管理着一个接收到的分组。
b. netif_receive_skb分析分组类型(协议类型),对给定的套接字缓冲区查找适当的处理程序,
根据分组类型将分组传递给该处理程序(网络层的接收函数,即传递到网络系统的更高一层)。
为此,该函数遍历所有可能负责当前分组类型的所有网络层函数,一一调用deliver_skb。
c. 接下来deliver_skb函数使用一个特定于分组类型的处理函数func,承担分组的更高层的处理。
d. 处理完退出的情况:
- 处理完了,没有超时,也没有超过预算
- 处理花费的时间超出netdev_budget_usecs(4.16.8定义的值为2000微秒)
- 处理的分组个数超出预算netdev_budget (4.16.8定义的值为300个)
- 没有处理完,则调用__raise_softirq_irqoff(NET_RX_SOFTIRQ) ,继续开启软中断,等待合适的时机再次处理
预算可通过proc配置,系统默认为300个 /proc/sys/net/core/netdev_budget
tcpdump抓包位置
所有从底层的网络访问层接收数据的网络层函数都注册在一个散列表中,通过全局数组ptype_base实现。
新的协议通过dev_add_pack增加。 各个数组项类型为struct packet_type
<netdevice.h>
struct packet_type {
__be16 type; /* This is really htons(ether_type). */
struct net_device *dev; /* NULL is wildcarded here */
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *);
...
void *af_packet_priv;
struct list_head list;
};
type 指定了协议的标识符,处理程序会使用该标识符。
dev将一个协议处理程序绑定到特定的网卡(NULL指针表示该处理程序对系统中所有网络设备都有效)。
func 指向网络层函数的指针,如果分组的类型适当,将其传递给该函数。其中一个处理程序就是ip_rcv,用于ipv4的协议。
- 接收路径
__netif_receive_skb_core 中遍历 ptype_all 链表static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev) { .... list_for_each_entry_rcu(ptype, &ptype_all, list) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } ..... } - 发送路径
dev_queue_xmit_nit 中遍历 ptype_all 链表void dev_queue_xmit_nit(struct sk_buff *skb, struct net_device *dev) { struct packet_type *ptype; struct sk_buff *skb2 = NULL; struct packet_type *pt_prev = NULL; struct list_head *ptype_list = &ptype_all; rcu_read_lock(); again: list_for_each_entry_rcu(ptype, ptype_list, list) { ..... if (pt_prev) { deliver_skb(skb2, pt_prev, skb->dev); pt_prev = ptype; continue; } ...... }
NAPI
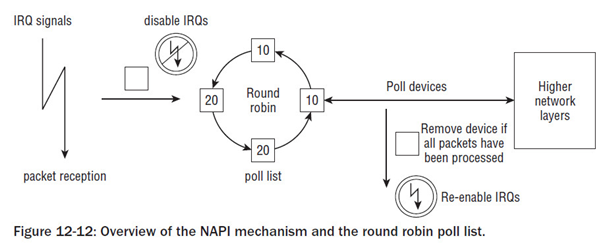
内核以轮询方式处理链表上的所有设备,依次轮询各个设备,如果已经花费了一定的时间来处理某个设备,则选择下一个设备进行处理。
某个设备都带有一个相对权重,表示与轮询表中其他设备相比,该设备的重要性。
较快的设备权重较大,较慢的设备权重较小。
由于权重指定了在一个轮询的循环中处理多少分组,这就确保了内核将更多地注意速度较快的设备。
第一个分组将导致网络适配器发出IRQ。
为防止进一步的分组导致发出更多的IRQ,驱动程序会关闭适配器的Rx IRQ。
并将该适配器放到一个轮询链表上。
只要适配器上还有分组需要处理,内核就一直对轮询表上的设备进行轮询。重新启用Rx中断。
适用场合
-
对于上层的应用程序而言,系统不能在每个数据包接收到的时候都可以及时地去处理它,而且随着传输速度增加,累计的数据包将会耗费大量的内存。
-
对于大的数据包处理比较困难,原因是大的数据包传送到网络层上的时候耗费的时间比短数据包长很多
由此可见, NAPI 技术适用于对高速率的短长度数据包的处理。
对设备的要求
设备必须能够保留多个接收的分组,例如保存到DMA环形缓冲区中,即Rx缓冲区。
该设备还必须能够禁用用于分组接收到IRQ,而且,发送分组或其他可能通过IRQ进行的操作,都仍然是启用的。
代码实现
支持NAPI的设备必须提供一个Poll函数,该方法特定于设备,在用netif_napi_add注册网卡时指定。调用该函数注册,表明设备可以且必须用新方法处理。
/**
* netif_napi_add() - initialize a NAPI context
* @dev: network device
* @napi: NAPI context
* @poll: polling function
*
* netif_napi_add() must be used to initialize a NAPI context prior to calling
* *any* of the other NAPI-related functions.
*/
static inline void
netif_napi_add(struct net_device *dev, struct napi_struct *napi,
int (*poll)(struct napi_struct *, int))
{
netif_napi_add_weight(dev, napi, poll, NAPI_POLL_WEIGHT);
}
Poll 函数实现
获取特定于设备的信息,调用特定于硬件的xx_poll方法,执行所需要的底层操作,
从网络适配器获取分组,把接收的报文转换为skb_buff进行处理,然后调用netif_receive_skb将分组传递到网络实现的高层。
xx_poll 根据budget处理分组个数。返回实际上处理的分组的数目。分为两种情况:
a.处理的分组数目小于budget, Rx缓冲区为空,内核从轮询表移除该设备。然后驱动程序必须通过特定于硬件的方法重新启用IRQ。
b.已经完全用掉了预算,但仍然有更多的分组需要处理,则设备仍然留在轮询表上,不启用中断。
IRQ实现
通知内核有新的分组到达,即调用__napi_schedule: 把设备放置到轮询表上,并引发NET_RX_SOFTIRQ软中断。
RX SoftIRQ 实现
内核通过依次调用各个设备特定的poll方法,处理轮询表上当前的所有设备。
NAPI和非NAPI之间的两点差异
-
NAPI驱动必须提供poll方法(由netif_napi_add注册poll方法,参考例e1000_probe)
-
驱动程序调用接口不同
-
NAPI 驱动程序调用 __napi_schedule (e1000以太驱动中断处理函数e1000_intr)
把自己放到per-cpu的sd->poll_list设备链表上然后调用触发软中断
之后NET对应的软中断处理函数net_rx_action会调用设备驱动poll方法,会直接从设备(或者设备驱动程序的接收环)中取出帧 -
非NAPI 驱动程序调用netif_rx (vortex_rx) 调用该函数标志着控制由特定于网卡的代码转移到了网络层的通用接口部分
非NAPI驱动接收处理
netif_rx将接收到的分组放置到一个特定于CPU的等待队列上(sd->input_pkt_queue),
调用____napi_schedule,把自己放到softnet_data->poll_list设备链表上,然后触发软中断
netif_rx –> enqueue_to_backlog
net_rx_action –> poll (即process_backlog)
只有非NAPI设备才会使用enqueue_to_backlog和process_backlog
所以说backlog dev是一个为了适配NAPI接口的伪设备,只是为了在软中断net_rx_action中统一调用poll方法
net_dev_init中为每个CPU 初始化 softnet_data
static int __init net_dev_init(void)
{
.....
for_each_possible_cpu(i) {
struct softnet_data *sd = &per_cpu(softnet_data, i);
.....
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
......
}
网络驱动程序
设备注册
驱动程序要探测其设备和硬件位置(I/O端口及IRQ线),但不需要注册。
而对每个新检测到的接口,向全局的网络设备链表中插入一个数据结构。每个接口由一个net_device 结构描述。
struct net_device *alloc_netdev(int sizeof_priv, const char *name,
void (*setup)(struct net_device *));
打开和关闭
netif_start_queue(dev);
netif_stop_queue(dev); 该函数也可用来临时停止传输。
驱动程序可在装载阶段或内核引导阶段调用探测接口。
但是在接口能够传送数据包之前,内核必须打开接口并赋予其地址。
内核可在响应ifconfig命令时打开或关闭接口。
Open请求必要的系统资源,并告诉接口开始工作
-
要将地址可在打开期间拷贝到设备中。在接口能够和外界通讯之前,要将要将地址(MAC)从硬件设备复制到dev->dev_addr
-
准备好开始传输数据后,open方法还应该启动接口的传输队列(允许接口接收传输数据包)。
数据包传输
无论何时内核要传输一个数据包,它都会调用驱动程序的hard_start_xmit函数将数据放入外发队列。
每个接口驱动程序都必须根据其驱动的特有硬件实现tx传输代码。
控制并发传输
实际的硬件接口异步方式传输数据包,而且可用来保存外发数据包的存储空间非常有限。
在内存被耗尽时,驱动程序需要告诉系统,在硬件能够接收新数据之前,不能启动其他数据包传输。
netif_stop_queue 可完成这一通知,禁止队列传输。
netif_wake_queue 启动队列传输。
传输超时
大部分处理实际硬件的驱动程序必须能够应付硬件偶尔不能正常响应的问题。接口也许会忘记它在做什么,或者系统有可能丢失中断。
这种类型的问题在个人计算机上的某些设备中很常见。
许多驱动程序利用定时器处理这类问题;如果某个操作在定时器到期时还未完成,则认为出现了问题。
Tx_timeout 如果当前的系统时间超过设备的trans_start时间至少一个超时周期,网络层将最终调用驱动程序的tx_timeout函数。 这个函数的任务是完成解决超时问题而需要的任何工作,并确保正在进行的任何传输能够正常结束。驱动程序不能丢死网络代码提交的套接字缓冲区,这一点尤其重要。
分散/聚集 I/O
在网络上为传输个创建数据包的过程,包括了组装多个数据片段的过程。
数据包中的数据需要从用户空间拷贝出来,并且针对各种不同层次的网络协议栈添加数据头。
这个组装过程包含了大量的数据拷贝各工作。如果负责发送数据包的网络接口实现了分散/聚集 I/O,则数据包就不用组装成一个大的数据块,而且省去了许多拷贝操作。
分散/聚集 I/O还能用“零拷贝”的方法,把网络数据直接从用户空间缓冲区内传输出去。
数据包的接收
- 中断驱动方式
- 轮训方式
- NAPI 结合了中断和轮训的方式
中断处理函数
接口可能在两种可能的事件下中断处理器:新数据包到达,或者外发数据包的传输已经完成。网络接口还能产生中断以通知错误的产生、连接状态等情况。
通常中断例程通过检查物理设备中的状态寄存器(使用I/O指令),以区分新数据包到达中断和数据传输完毕中断。
链路状态的变化
void netif_carrier_off(struct net_device *dev);
void netif_carrier_on(struct net_device *dev);
int netif_carrier_ok(struct net_device *dev);
参考索引
《深入linux内核架构》
《精通linux内核网络》
《linux设备驱动程序》
《深入理解LINUX网络内幕》