MESI协议
该协议用于解决高速缓存一致性问题,理解该协议可以参考文章末尾链接里的论文。
这里只摘录其中两个和使无效队列相关的消息
失效(Invalidate):失效消息包含需要失效的缓存行的物理地址。
所有持有该缓存行副本(状态为Shared或Modified)的其他缓存,必须将对应缓存行状态置为Invalid,并发送Invalidate Acknowledge。
失效确认(Invalidate Acknowledge):接收到失效消息的CPU必须在从其缓存中移除指定数据后,通过发送一个失效确认消息来做出响应。
内存乱序
高速缓存虽然降低了cpu对内存的访问延迟,但是指令流水线还是会因为cache missing而停滞。
CPU设计者为了使CPU流水线更加顺畅,实现更好的性能,硬件上引入了Store Buffer和Invalidate Queue两个组件。
这两个组件的引入都有可能导致内存乱序。因为硬件线程的内存操作从该核的角度来看是有序的,但从其他核的角度来看可能是无序的。
这为编写功能正确且高性能的代码带来了挑战。
高速缓存一致性MESI协议只是在多个cpu上了保证cache数据的一致性,但是硬件并不懂得程序代码逻辑,
比如一个cpu上执行的前后两个相邻的不同变量赋值可能会影响到另一个cpu上前后两个相邻的不同变量的读取,从而改变程序逻辑,导致错误。
详细解释可以参考文末论文。
下面介绍下这两个组件。
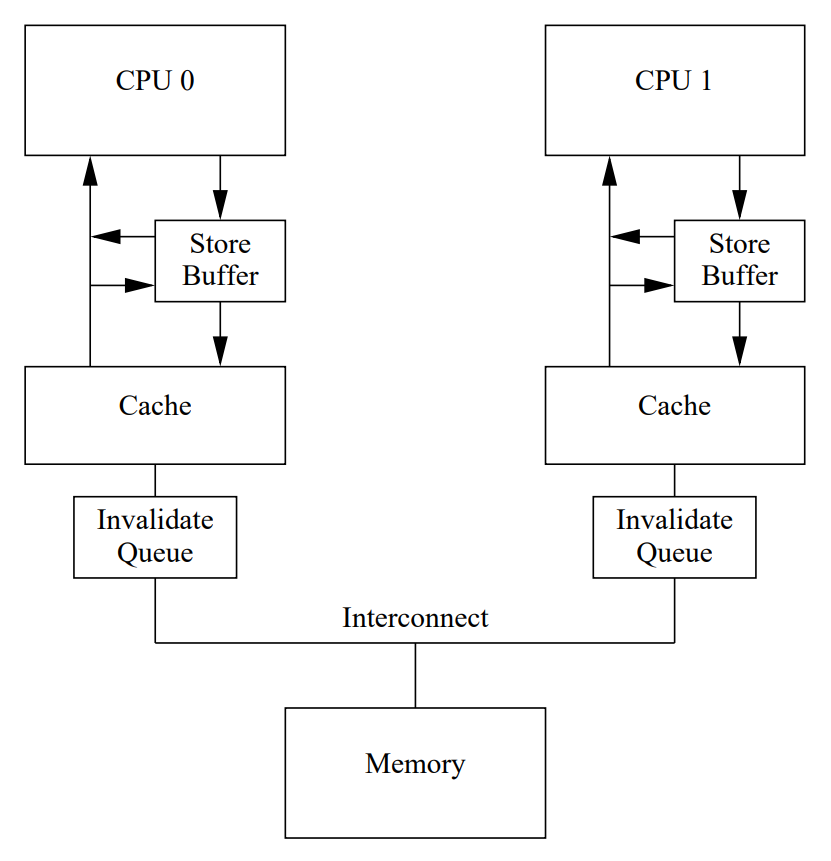
Store BUffer
比如给共享变量赋值的操作,该变量在当前CPU上cache缺失的情况下,需要停滞等待cache行返回数据。
但实际上没有必要让CPU长时间停滞,无论其它CPU发送给它的缓存行中包含什么数据,当前cpu执行赋值操作都会无条件地覆盖它。
防止这种不必要的写入停顿的一种方法是在每个CPU和其缓存之间添加存储缓冲区(store buffer)
通过添加这些存储缓冲区,CPU可以简单地将其写入记录在存储缓冲区中并继续执行。
当缓存行最终从其它CPU传递到当前CPU时,数据将从存储缓冲区移动到高速缓存行中。
不幸的是,每个存储缓冲区必须相对较小,这意味着执行适度的存储序列的CPU可能会填满其存储缓冲区
例如,如果所有这些存储都导致缓存未命中,此时,CPU必须再次等待使失效完成,以便在继续执行之前排空其存储缓冲区。
在内存屏障之后,情况可能会立即发生,此时所有后续的存储指令都必须等待使失效完成,无论这些存储是否导致缓存未命中
通过加快使失效确认消息的到达,可以改善这种情况。一种实现这一目标的方式是使用每个CPU的使失效消息队列,或者称为“使失效队列”。
invalidate queue
比如给共享变量赋值的操作,该变量在当前CPU上cache的情况
但是在给定CPU对某个数据项进行写操作之前,需要确保所有CPU都对该数据项的值达成一致,
所以首先必须将该数据项从其他CPU的缓存中删除或“失效”。一旦这个失效操作完成,CPU就可以安全地修改数据项。
如果数据项已经存在于该CPU的缓存中,但是是只读的,这个过程称为“写失效”。
一旦CPU获得该缓存行的Modified状态(意味着独占所有权且其他所有缓存行副本已失效),
它就可以直接修改其本地缓存行,无需再广播通知,直到该行被驱逐或需要共享/传递数据。
使失效确认消息可能需要很长时间的一个原因是,它们必须确保相应的缓存行实际上已被使失效,
发送使失效的cpu必须收到其它cpu发出的使失效确认才可以放心的写入数据,这也会导致cpu停滞
如果缓存正在忙于加载和存储数据(例如,如果CPU正在密集地执行这些操作),则使失效可能会被延迟。
此外,如果在短时间内收到大量的使失效消息,某个CPU可能会落后于处理这些消息,从而可能使所有其他CPU停滞。
然而,CPU实际上不需要在发送确认消息之前使缓存行无效。
相反,它可以将使失效消息排入队列,并理解消息将在CPU发送有关该缓存行的任何进一步消息之前被处理。
具有使失效队列的CPU可以在使失效消息放入队列后立即确认该消息,而不必等待相应的缓存行实际上被使失效。
这正是导致“Load-Load/Load-Store”乱序的直接原因。
CPU A认为B的缓存已失效(因为收到了Ack),但实际上B的CPU核心可能还在使用其本地缓存中的旧值(因为Invalidate还在队列里没处理)。
当然,当准备发送使失效消息时,CPU必须参考其使失效队列
如果使失效队列中有相应缓存行的条目,则CPU不能立即传输使失效消息;相反,它必须等到使失效队列中的条目被处理完毕才能传输。
将条目放入使失效队列实质上只是CPU的承诺,在发送任何有关该缓存行的MESI协议消息之前处理该条目。
只要相应的数据结构不受高度竞争,CPU很少会受到这种承诺的不便。
然而,使失效消息可以在使失效队列中进行缓冲,这为内存乱序提供了额外的机会。
引入内存屏障
内存屏障有两个作用:
- 阻止屏障两侧的指令重排
- 将Store Buffer中的写操作刷新到CPU自己的缓存层,并触发MESI协议流程(使其他核缓存失效)
volatile能够阻止编译器调整顺序,却无法阻止cpu动态调度换序(乱序执行)。
可以用volatile关键字阻止编译器过度优化,volatile基本可以做到两件事情:
- 阻止编译器为了提高速度将一个变量缓存到寄存器内而不写回
- 阻止编译器调整操作volatile变量的指令顺序
内存屏障是硬件层的概念,不同的硬件平台实现内存屏障的手段不相同。硬件层的内存屏障分为两种:
-
Load Barrier读屏障
在指令前插入,可以让高速缓存中的数据失效,强制重新从主内存加载数据,即达到获取最新数据的目的
读端的屏障,它解决使无效队列引入的内存乱序,读端内存屏障指令能够与使无效队列交互,
这样,当一个特定的CPU执行一个读内存屏障时,它标记无效队列中的所有条目,
并强制所有后续的装载操作进行等待,直到所有标记的条目对应的缓存行状态在本核缓存中置为Invalid。 -
Store barrier写屏障
在指令后插入,能让写入缓存中的最新数据更新写入主内存,使更新后的数据为其它线程可见
写端的屏障,它解决Write buffer引入的内存乱序
许多CPU架构提供了更弱的内存屏障指令,仅对这两者中的一个进行标记。
粗略地说,”读内存屏障”仅标记使失效队列,而”写内存屏障”仅标记存储缓冲区。而完整的内存屏障则两者都进行标记。
这样做的效果是,读内存屏障仅对执行它的CPU上的加载进行排序,因此在读内存屏障之前的所有加载都已在读内存屏障之前完成。
类似地,写内存屏障仅对执行它的CPU上的存储进行排序,因此在写内存屏障之前的所有存储都已在写内存屏障之前完成。
完整的内存屏障则同时对加载和存储进行排序,但仍仅对执行内存屏障的CPU上的操作进行排序。
对应内核三个变种
smp_mb()
smp_rmb()
smp_wmb()
内存屏障被用于标记存储缓冲区和使失效队列中的条目。
但在如下代码片段中,foo()没有理由与使失效队列交互,而bar()同样没有理由与存储队列交互。
完全(双向)内存屏障虽然不会影响功能的正确性,但可能会影响性能。
所以可以把完整(双向)内存屏障替换成读或写内存屏障。
与完整(双向)内存屏障一样,这对于功能上的正确性是足够的,同时它对内存操作的重新排序施加了较少的限制,
所以单向的内存屏障的开销比使用完整的双向屏障来进行同步要小。
1 void foo(void)
2 {
3 a = 1;
4 smp_wmb(); // smp_mb()替换为 smp_wmb()
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_rmb(); // smp_mb()替换为 smp_rmb()
12 assert(a == 1);
13 }
参考
Memory Barriers: a Hardware View for Software Hackers