简介
原子操作需要处理器提供硬件支持,不同的处理器体系结构在原子操作上会有不同的实现。
对riscv架构来说,就是A扩展,也被称为原子指令集扩展。
包含了一些指令,可以原子地读取、修改和写入内存,主要是为了在同一内存空间中的多个RISC-V处理器之间提供同步。
A扩展提供了两种类型的原子指令,分别是原子fetch-and-op内存(AMO)指令和load-reserved/store-conditional(LR/SC)指令。
LR/SC指令
LR(Load-Reserved)指令用于从内存加载一个值,并将该值存储在特定的寄存器中。
同时,它会标记一个内存位置,防止其他线程在LR和SC之间对该内存位置进行写操作。
SC(Store-Conditional)指令用于将一个值存储到内存位置,但仅当在上一个LR指令之后,该内存位置没有被其他线程修改过。
如果LR和SC之间发生了写操作,SC指令将会失败,不会执行存储操作。
LR/SC类型的原子指令适用于对共享内存进行短期访问的情况,
因为在SC指令中,如果检测到其他线程已经修改了该内存位置,就会导致SC指令失败,需要重新尝试。
编程语言的开发者会假定体系结构提供了原子的比较 -交换( compare-and-swap)操作:
比较一个寄存器中的值和另一个寄存器中的内存地址指向的值,如果它们相等,将第三个寄存器中的值和内存中的值进行交换。
这是一条通用的同步原语,其它的同步操作可以以它为基础来完成。
利用 LR/SC 指令,可以实现 CAS(Compare and swap) 操作,代码如下:
retry:
lr.w a3, (a0) 从a0加载现在的旧值到a3
bne a3,a1, fail 比较现有的旧值和预期的旧值,不相等就跳出去,交换失败
sc.w a3,a2,(a0) 把新值写入a0指向的内存地址,并把写入成功与否的结果写入a3寄存器(0表示写入成功,非0表示写入失败)
bneqz a3, retry 如果a3不为0,表示写入失败,跳转到retry处继续尝试写入
success code after CAS ...
fail:
fail code after CAS ...
a0 旧值所在内存地址
a1 期望的旧值
a2 待写入的新值
a3 结果反馈
RISC-V 对 LR 和 SC 之间的指令是有限制的,一个是 LR 和 SC 之间最大只能包含 16 个指令,
另外这些指令只能使用基础整数指令集(指令集 “I”,不包含内存访问指令,跳转指令,fence 和 system 指令)。
如果违反了这些限制,LR/SC 指令的效果是不受约束的,可能在一些芯片实现上能保证原子性,在另外一些芯片实现上不能保证。
LR/SC指令在多核之间利用高速缓存一致性协议以及独占监视器保证执行的串行化与数据一致性。
要理解LR/SC指令的执行过程,需要根据独占监视器的状态以及MESI状态的变化来综合分析。
AMO指令
AMO实现提供fetch-and-op样式的原子基元,因为它们在高度并行的系统中比LR/SC或CAS更具扩展性。
允许以原子方式执行一系列的内存操作,包括交换、整数加法、按位AND、按位OR、按位XOR,以及有符号和无符号整数的最大值和最小值。
AMO指令的原子性保证了这一系列操作不会被其他线程中断,从而确保了多线程环境下的数据一致性。
AMO的另一个用途是在I/O空间中为内存映射的设备寄存器提供原子更新(例如,设置、清除或切换位)。
因为可以在单个原子指令中执行多个操作,并且不需要像LR/SC那样反复尝试,因此可以提供更高的性能。
对于AMO,A扩展要求rs1中保存的地址与操作数的大小自然对齐(即64位字为8字节对齐,32位字为4字节对齐)。
如果地址不是自然对齐的,将生成地址对齐异常或访问故障异常。
除了LR/SC,另外还提供AMO指令的原因是,在多处理器系统中拥有比加载保留/条件存储更好的可扩展性。
AMO指令在于I/O设备通信时也很有用,可以实现总线事务的原子读写。这种原子性可以简化设备驱动,并提高I/O性能。
二者区别
以下摘录自笨叔的《riscv体系结构编程与实现》一书,从硬件实现角度解释了两者的区别。
原子内存访问操作指令与独占内存访问指令最大的区别在于效率。
使用独占内存访问指令会导致所有cpu内核都把锁加载到各自的L1高速缓存中,
然后不停地尝试获取锁(使用LR指令来获取锁)并检查各自的独占监视器的状态,导致高速缓存颠簸。
这个场景在NUMA体系结构下回变得更加糟糕,远端节点的CPU需要不停的跨越节点访问数据。
另外一个问题是不公平,当锁的持有者释放锁时,所有的CPU都需要抢这个锁(使用SC指令写这个lock变量),
有可能最先申请锁的cpu反而没有抢到锁。
如果使用原子内存访问操作指令,
那么最先申请这个锁的cpu内核会通过CHI总线的HN-F节点完成算数和逻辑运算,
不需要把数据加载到L1高速缓存,而且整个过程都是原子的。
访存顺序限制
RISC-V具有宽松的内存一致性模型(relaxed memory consistency model) 因此其他线程看到的内存访问可以是乱序的。
在不施加额外限制的情况下,内存访问指令并不会完全按照指令顺序执行。
RISC-V 有一个 FENCE 指令,可以用来显式添加内存顺序限制。
为了提高效率,RISC-V 为每个原子指令都预留 aq/rl 两个比特位,从而可以很方便在原子指令上施加额外的内存顺序限制。
原子指令是用来在不同 hart 之间做同步用的,而内存访问顺序强调的是同一个 hart 内的执行顺序。
LR/SC 和 AMO 指令,每个指令后面都带有一个 “aqrl” 的可选后缀。aq 是 acquire 的缩写,rl 是 release 的缩写。
LR/SC 和 AMO 指令就是通过这两个后缀来添加额外的内存顺序限制。
RISC-V体系结构仅支持在LR/SC和AMO指令中内嵌获取和释放屏障原语。
| Acquire | Release | 含义 |
|---|---|---|
| 0 | 0 | 没有顺序限制 |
| 0 | 1 | 该指令前序所有访问存储的指令的结果必须在该指令执行之前被观察到 |
| 1 | 0 | 该指令后序所有访问存储的指令必须等该指令执行完成后才开始执行 |
| 1 | 1 | 该指令前序所有访问存储的指令的结果必须在该指令执行之前被观察到,该指令后序所有访问存储的指令必须等该指令执行完成后才开始执行 |
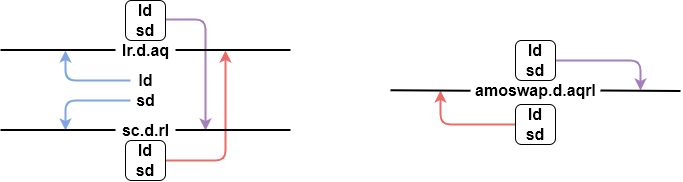
aq 标志位会限制所有后面内存访问指令,rl 标志位会限制所有前面内存访问指令,而 aqrl 是前两者的效果叠加。
分别使用 aq 和 rl 标志位,可以人为的划定一个范围,把这两者之间的内存访问指令框起来。
虽然 RISC-V 为每个原子指令都预留了 aq/rl 比特位,但对于一些特定指令,aq/rl 不能随便设置。
比如 lr.d.rl 和 sc.d.aq 指令是没有实际意义的,RISC-V 并没有直接禁止这种用法,但这种指令没有预期的原子访问效果。
spin_lock 实现
spin_lock就利用了amo指令用于多核同步。
amoadd.w.aqrl a5,a5,(s1) 原子指令同时叠加了内存屏障的效果,aqrl限制了amo指令前后的访存指令排序
typedef struct {
int counter;
} atomic_t;
typedef atomic_t arch_spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
void do_raw_spin_lock(raw_spinlock_t *lock)
{
debug_spin_lock_before(lock);
arch_spin_lock(&lock->raw_lock);
mmiowb_spin_lock();
debug_spin_lock_after(lock);
}
static __always_inline void arch_spin_lock(arch_spinlock_t *lock)
{
u32 val = atomic_fetch_add(1<<16, lock); // lock->counter原子地加上 0x10000,返回旧值存储到val
u16 ticket = val >> 16;
// lock->counter 高16位为当前正在服务的ticket,低16位为自己的ticket,只有二者相等的情况,才能轮到自己拿锁
if (ticket == (u16)val)
return; // 拿锁成功
// 还没轮到自己拿锁
/*
* atomic_cond_read_acquire() is RCpc, but rather than defining a
* custom cond_read_rcsc() here we just emit a full fence. We only
* need the prior reads before subsequent writes ordering from
* smb_mb(), but as atomic_cond_read_acquire() just emits reads and we
* have no outstanding writes due to the atomic_fetch_add() the extra
* orderings are free.
*/
atomic_cond_read_acquire(lock, ticket == (u16)VAL);
smp_mb();
}
gdb) disassemble do_raw_spin_lock
Dump of assembler code for function do_raw_spin_lock:
0xffffffff80069d9a <+0>: addi sp,sp,-32
0xffffffff80069d9c <+2>: sd s0,16(sp)
0xffffffff80069d9e <+4>: sd s1,8(sp)
0xffffffff80069da0 <+6>: sd ra,24(sp)
0xffffffff80069da2 <+8>: addi s0,sp,32
0xffffffff80069da4 <+10>: lw a4,4(a0) // 加载 lock->magic 到 a4 寄存器
0xffffffff80069da6 <+12>: lui a5,0xdead5
0xffffffff80069daa <+16>: addi a5,a5,-339 # 0xffffffffdead4ead
0xffffffff80069dae <+20>: sext.w a4,a4
0xffffffff80069db0 <+22>: mv s1,a0
0xffffffff80069db2 <+24>: bne a4,a5,0xffffffff80069e32 <do_raw_spin_lock+152> // 比较 lock->magic
0xffffffff80069db6 <+28>: ld a5,16(s1) // lock->owner
0xffffffff80069db8 <+30>: beq a5,tp,0xffffffff80069e50 <do_raw_spin_lock+182> // 比较 lock->owner
0xffffffff80069dbc <+34>: lw a5,8(s1) // lock->owner_cpu
0xffffffff80069dbe <+36>: lw a4,32(tp) # 0x20
0xffffffff80069dc2 <+40>: sext.w a5,a5
0xffffffff80069dc4 <+42>: beq a4,a5,0xffffffff80069e6e <do_raw_spin_lock+212> // 比较 lock->owner_cpu
0xffffffff80069dc8 <+46>: lui a5,0x10
0xffffffff80069dca <+48>: amoadd.w.aqrl a5,a5,(s1) // 内存原子操作,执行原子加法,并将结果存储在寄存器 a5 中
0xffffffff80069dce <+52>: srliw a4,a5,0x10 // a4 = a5 >> 16 a4中保存着自己的ticket
0xffffffff80069dd2 <+56>: slli a5,a5,0x30 // a5 = a5 << 48
0xffffffff80069dd4 <+58>: srli a5,a5,0x30 // a5 = a5 >> 48 a5中保存着正在处理的tiacket
0xffffffff80069dd6 <+60>: bne a4,a5,0xffffffff80069de4 <do_raw_spin_lock+74> // if (ticket != (u16)val) 说明多个cpu同时拿锁,并且还没轮到自己拿锁
0xffffffff80069dda <+64>: j 0xffffffff80069df6 <do_raw_spin_lock+92> // 拿锁成功 只有 ticket == (u16)val 的cpu会拿锁成功
0xffffffff80069ddc <+66>: div a5,a5,zero // 这两条指令看着有点奇怪,不知道要达成什么目的
0xffffffff80069de0 <+70>: fence w,unknown // 也没搜到权威的解释
0xffffffff80069de4 <+74>: lw a5,0(s1) // 从内存获取最新的lock->counter数值
0xffffffff80069de6 <+76>: slli a5,a5,0x30 //
0xffffffff80069de8 <+78>: srli a5,a5,0x30 // a5中保存着当前正在处理的ticket,a4中是自己的ticket
0xffffffff80069dea <+80>: bne a4,a5,0xffffffff80069ddc <do_raw_spin_lock+66> // 根据ticket判断拿锁失败,循环尝试拿锁
0xffffffff80069dee <+84>: fence r,r
0xffffffff80069df2 <+88>: fence rw,rw
0xffffffff80069df6 <+92>: lw a5,32(tp) # 0x20 // 拿锁成功
......
参考
https://five-embeddev.com/riscv-isa-manual/latest/a.html
https://elixir.bootlin.com/linux/v6.2/source
https://tinylab.org/riscv-atomics/
《RISC-V体系结构编程与实践》
《RISC-V-Reader-Chinese-v2p1.pdf》