简介
PLIC(platform-level interrupt controller),平台级中断控制器。
PLIC将各种设备中断复用到Hart上下文的外部中断线上,具有硬件支持的中断优先级。
PLIC支持最多1023个中断(0号中断保留) 和15872个上下文,但实际中断和上下文的数量取决于PLIC的实现。
PLIC规范中声称支持15872个上下文,这个数字是基于对多个中断目标和中断源的支持所得出的。
在一个典型的系统中,有多个处理器核心(harts)以及每个核心可以处于不同的特权级别(例如,机器模式、监管模式等)。
每个处理器核心可能需要处理来自多个不同源的中断。为了支持这种情况,PLIC需要跟踪每个核心的中断状态,以及每个特权级别的中断状态。
每个处理器核心及其所处的特权级可以看作一个上下文。
如果有大量的核心(比如多核处理器),并且每个核心还支持多个特权级别(比如不同的运行模式),那么可能会有大量的中断上下文需要管理。
因此,PLC规范中提到的15872个上下文是一个相对较大的数目,旨在支持多核、多特权级别以及大量中断源的复杂系统。
比如四个核,不支持SMT,理论上管理需要4 (cpu) * 2 (S + M) = 8 个contexts;
如果opensbi已经把外设中断委托给S模式的系统,M模式的hart不再处理plic外设中断,所以中断目标只需针对S模式的harts。
那么实际上运行在S模式下的plic只需要跟踪记录4个有效的contexts。
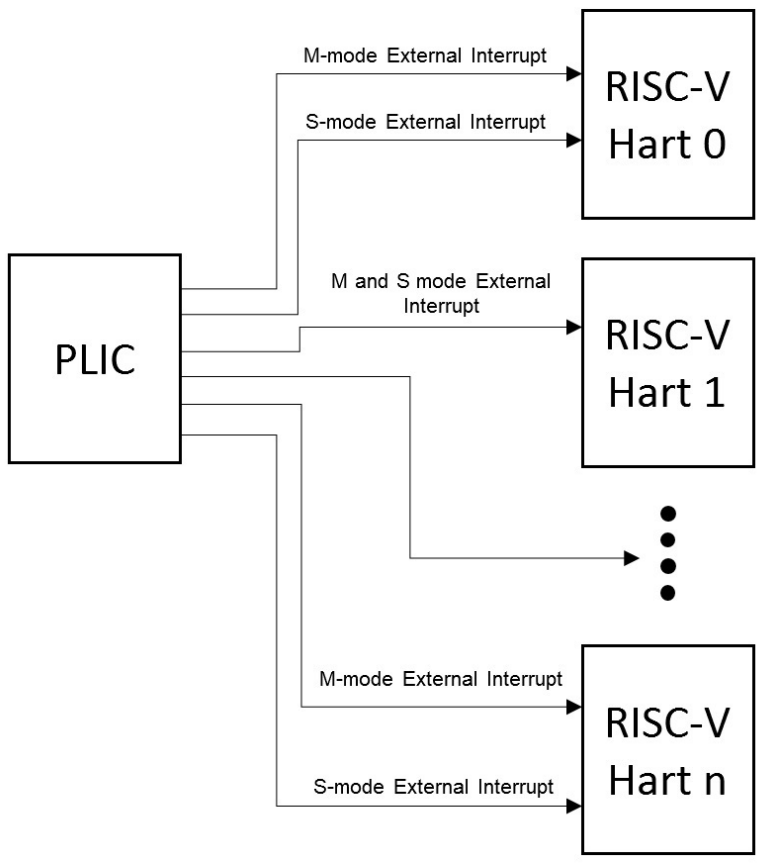
中断目标和hart上下文
中断目标通常是hart上下文,其中hart上下文是给定hart上的特定特权模式(尽管还有其他可能的中断目标,比如DMA引擎)。
例如,在一个具有2路SMT的4核系统中,您有8个harts,并且每个hart可能至少有两种特权模式:机器模式(M)和监管者模式(S)。
并非所有hart上下文都需要成为中断目标,特别是如果处理器核心不支持将外部中断委派给较低特权模式,那么较低特权的hart上下文将不会成为中断目标。
由PLIC生成的中断通知分别出现在M/S模式的mip/sip寄存器的meip/seip位中。
每个处理器核心都必须定义一个策略,以确定核心上多个hart上下文同时活动的中断如何被接管。
对于只有一个hart上下文堆栈的简单情况,每个支持的特权模式都有一个,对于较高特权上下文的中断可以抢占执行较低特权上下文的中断处理程序。
多线程处理器核心可以在不同的hart上下文上同时运行多个独立的中断处理程序。
处理器核心还可以提供仅用于中断处理的hart上下文,以减少中断服务延迟,这些上下文可能会抢占同一核心上其他harts的中断处理程序。
PLIC独立处理每个中断目标,不考虑包含多个中断目标的组件使用的任何中断优先级方案。
因此,PLIC没有提供中断抢占或嵌套的概念,因此必须由托管多个中断目标上下文的核心来处理这一点。
中断网关
中断网关负责将全局中断信号转换为通用中断请求格式,并控制中断请求流向PLIC核心。
在PLIC核心中,每个中断源每次只能有一个中断请求处于等待状态,通过设置源的IP位来指示。
在收到来自同一源的先前中断请求的处理完成通知后,中断网关才会将新的中断请求转发到PLIC核心。
中断通知
每个中断目标在PLIC核心中都有一个外部中断待处理(EIP)位,该位指示对应的目标有一个待处理中断等待服务。
EIP中的值可能会因为PLIC核心中的状态变化而改变,这些变化是由中断源、中断目标或其他代理操作PLIC中的寄存器值引起的。
EIP中的值被作为中断通知传递给目标。如果目标是RISC-V hart上下文,中断通知将根据hart上下文的特权级别在meip/seip位上到达。
(在简单的系统中,中断通知将是连接到实现hart的处理器的简单线路。在更复杂的平台上,这些通知可能会作为消息通过系统互连路由。)
PLIC硬件仅支持中断的多播,这意味着所有已启用的目标将为给定的活动中断接收中断通知。
(多播提供快速响应,因为最快的响应者会声明中断,但在高中断率情况下,如果多个hart为只有一个hart可以成功声明的中断而陷入陷阱,则可能会产生浪费。
作为每个中断处理程序的一部分,软件可以调制PLIC IE位以提供替代策略,例如中断关联性或循环单播。)
根据平台架构和用于传输中断通知的方法,这些通知可能需要一些时间才能被目标接收到。
只要在PLIC核心中没有干预活动,PLIC保证最终将所有EIP中的状态变化传递给所有目标。
(中断通知中的值仅保证在过去的某个时间点上保持有效的EIP值。
特别地,当第一个目标的通知仍在传输过程中时,第二个目标可以响应并声明一个中断,因此当第一个目标尝试声明中断时,它会发现在PLIC核心中没有活动的中断。)
中断标识符
中断标识符(IDs)全局中断源被分配了从值1开始的小的无符号整数标识符。中断ID为0保留表示“无中断”。
当两个或多个中断源具有相同的分配优先级时,中断标识符也用于解决冲突。较小的中断ID的值优先于较大的中断ID的值。
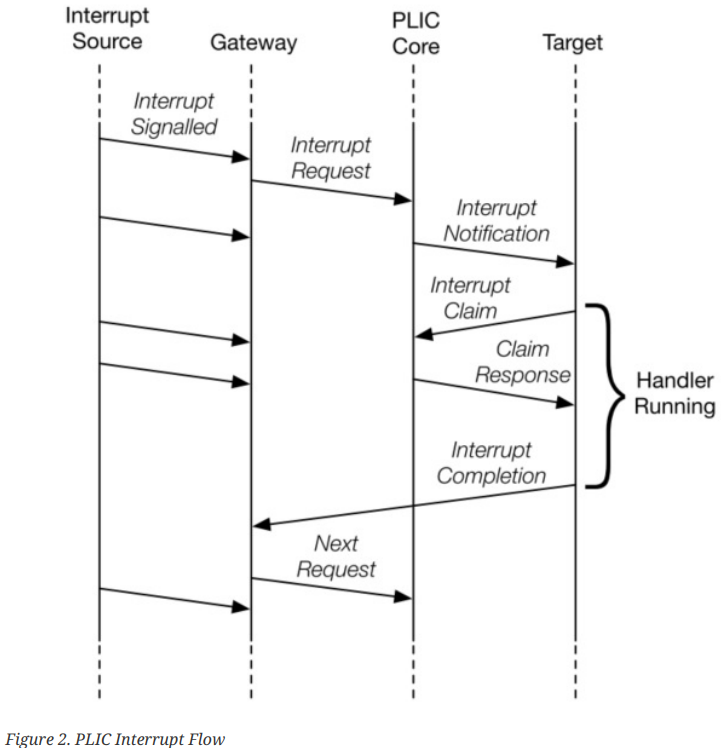
中断流程
下图显示了在通过PLIC处理中断时,代理之间的消息流动。
• 全局中断从其源发送到处理每个源的中断信号的中断网关。
• 中断网关将单个中断请求发送到PLIC核心,这些请求被锁存到核心中的中断挂起位(IP)中。
• 如果目标启用了任何挂起中断并且挂起中断的优先级超过了每个目标的阈值,PLIC核心会向一个或多个目标转发中断通知。
• 当目标接受外部中断时,它发送一个中断认领请求,以从PLIC核心检索待处理的针对该目标的最高优先级全局中断源的标识符。
• PLIC核心然后清除相应的中断源待处理位。
• 在目标处理中断后,它向相关的中断网关发送中断完成消息。
• 现在,中断网关可以为同一源再次转发中断请求给PLIC。
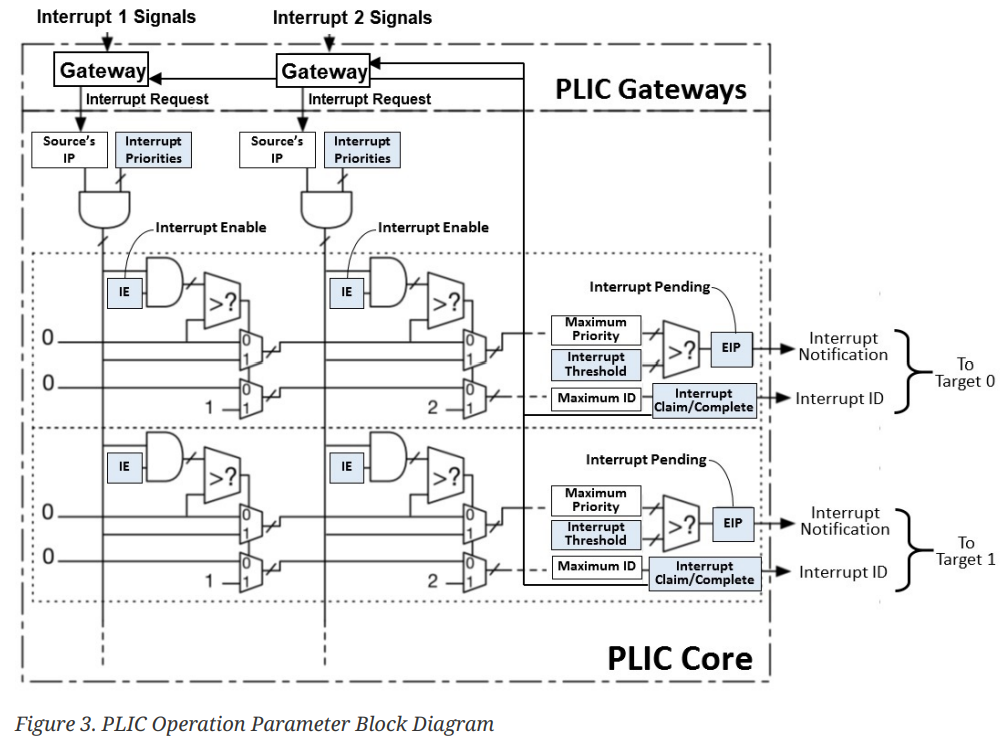
中断控制寄存器
通用PLIC操作参数寄存器包括:
• 中断优先级寄存器: 每个中断源的中断优先级。
• 中断待处理位寄存器: 每个中断源的中断待处理状态。
• 中断使能寄存器: 每个上下文中断源的启用状态。
• 优先级阈值寄存器: 每个上下文的中断优先级阈值。
• 中断认领寄存器: 获取每个上下文中断源ID的寄存器。
• 中断完成寄存器: 向关联网关发送中断完成消息的寄存器。
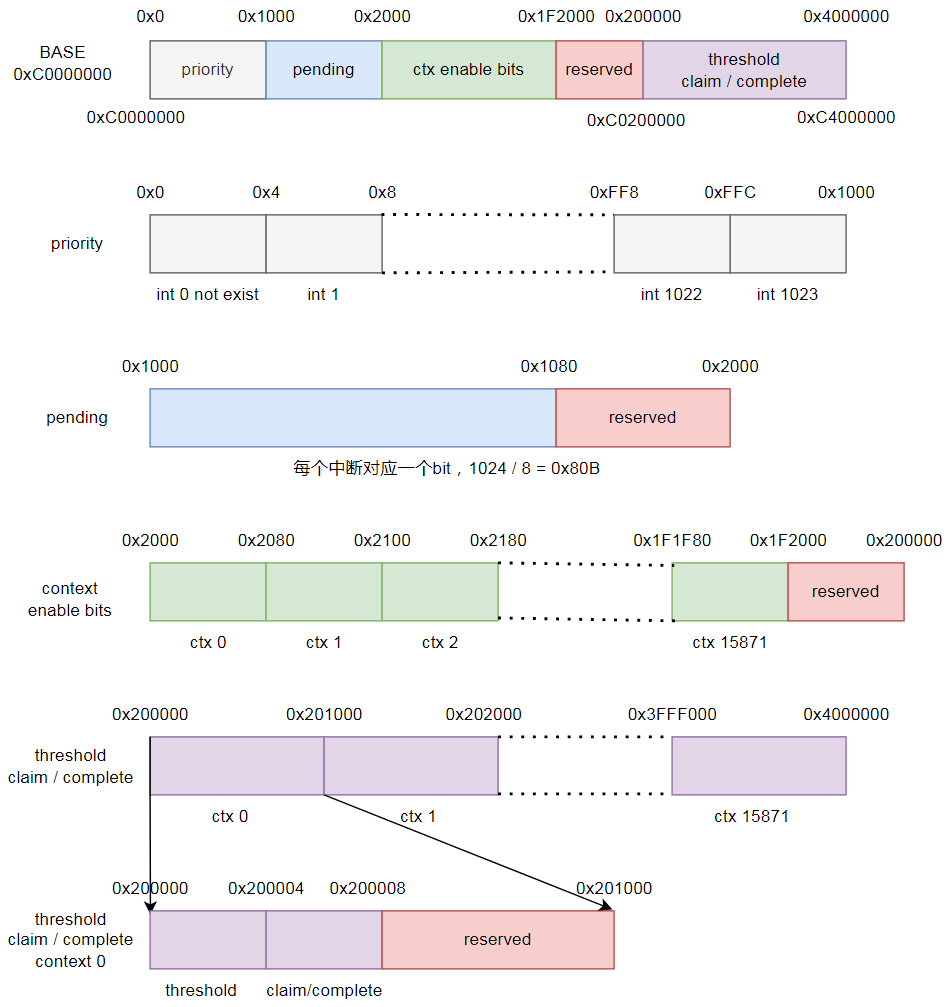
内存映射
PLIC内存映射的基地址是特定于平台实现的。
本章中指定的内存映射寄存器宽度为32位。这些位可以通过LW和SW指令进行原子访问。
如果PLIC满规格实现1023个中断和15872个上下文,寄存器地址范围如下图所示:
中断优先级
中断优先级是小的无符号整数,具有特定于平台的最大支持级别数。
优先级值0保留表示“永不中断”,中断优先级随着整数值增加而增加。
每个全局中断源都有一个关联的中断优先级,保存在一个内存映射寄存器中。不同的中断源不必支持相同的优先级值集合。
有效的实现可以将所有输入优先级级别硬连线。中断源优先级寄存器应该是WARL字段,以允许软件确定每个优先级规范中是否存在可读写位的数量和位置。
为了简化发现支持的优先级值,每个优先级寄存器必须支持在寄存器内部可变位中的任何值组合,
即如果寄存器中有两个可变位,那么在这些位中的所有四个值组合都必须作为有效的优先级级别运行。
如果PLIC支持中断优先级,则可以通过写入其32位内存映射优先级寄存器为每个PLIC中断源分配优先级。
优先级值0保留表示“永不中断”,并且有效地禁用了中断。优先级1是最低的活动优先级,而最大优先级水平取决于PLIC的实现。
相同优先级的全局中断之间的冲突由中断ID来解决;具有最低ID的中断具有最高的有效优先级。
位于PLIC内存映射区域内中断源优先级块的基地址固定为0x000000。
中断待处理位
在PLIC核心中,中断源待处理位的当前状态可以从组织为32位寄存器的待处理数组中读取。
中断ID N的待处理位存储在单词(N/32)的位(N mod 32)中。单词0的位0代表不存在的中断源0,被硬连线为零。
在PLIC核心中,可以通过设置关联的使能位然后执行索赔来清除待处理位。
位于PLIC内存映射区域内中断待处理位块的基地址固定为0x001000。
中断使能
每个全局中断都可以通过设置对应的位于使能寄存器中来启用。
使能寄存器0的位0表示不存在的中断ID 0,并被硬连线为0。PLIC为上下文提供最多15872个中断使能块。
PLIC如何为上下文(Hart和特权模式)组织中断超出了RISC-V PLIC规范的范围,但必须在供应商的PLIC规范中进行规范说明。
(在某些情况下,一些中断源只能路由到目标子集的情况下,可能会将大量潜在的IE位硬连线为零。
对于具有固定中断路由的嵌入式设备,较大数量的位可能会连接到1。
中断优先级、阈值和hart内部中断屏蔽在忽略外部中断方面提供了相当大的灵活性,即使全局中断源始终启用。)
位于PLIC内存映射区域内中断使能位块的基地址固定为0x002000。
优先级阈值
PLIC提供了基于上下文的阈值寄存器,用于设置每个上下文的中断优先级阈值。阈值寄存器是一个WARL字段。
PLIC将屏蔽小于等于阈值的优先级的所有PLIC中断。例如,阈值值为零允许所有非零优先级的中断。
优先级阈值寄存器块的基地址位于从偏移量0x200000开始的4K对齐位置。
中断认领过程
在目标收到中断通知后的某个时候,它可能会决定处理该中断。
目标向PLIC核心发送一个中断认领消息,通常会实现为非幂等的内存映射I/O控制寄存器读取。
在接收到认领消息后,PLIC核心会原子地确定目标的最高优先级待处理中断的ID,然后清除相应源的IP位。
然后,PLIC核心会将ID返回给目标。如果在处理认领时目标没有待处理中断,PLIC核心会返回ID为零的值。
在目标声明了最高优先级的待处理中断并且相应的IP位被清除后,其他低优先级的待处理中断可能会对目标可见,因此在声明后,PLIC EIP位可能不会被清除。
中断处理程序可以在退出处理程序之前检查本地的meip/seip/ueip位,以允许更有效地处理其他中断,而无需首先恢复中断的上下文并进行另一个中断陷阱。
即使EIP未设置,对于hart来说,始终可以执行认领。
hart可以将阈值值设置为最大值,以禁用中断通知,并改为使用定期的认领请求轮询活动中断,
尽管实现轮询的更简单方法是在特权模式x的相应xie寄存器中清除外部中断使能。
PLIC可以通过读取认领/完成寄存器执行中断认领,该寄存器返回最高优先级待处理中断的ID,如果没有待处理中断,则返回零。
成功的认领还会原子地清除中断源上的相应待处理位。PLIC可以随时执行认领操作,并且认领操作不受优先级阈值寄存器的设置影响。
中断认领过程寄存器是基于上下文的,位于从偏移量0x200000开始的4K对齐位置加4处。
在多CPU场景中,PLIC会仲裁所有处于pending状态的外部中断请求,然后将仲裁“胜出”的一个外部中断请求通知给所有的CPU,
CPU收到PLIC 的通知后,会向PLIC claim相对应的外部中断源的ID,一旦拿到ID,就会清除该外部中断源的pending状态,
所以当多个CPU争抢一个ID时只有一个能拿到ID,当然也可以通过配置PLIC将不同的外部中断分配给不同的CPU处理,以保持负载平衡。
plic相关代码
qemu默认dts中plic节点如下
plic@c000000 {
phandle = <0x9>;
riscv,ndev = <0x35>; // 这个PLIC支持的中断源数量为53
reg = <0x0 0xc000000 0x0 0x600000>; // 0xc000000 - 0xc600000是PLIC的寄存器区域
interrupts-extended = <0x8 0xb 0x8 0x9 0x6 0xb 0x6 0x9 0x4 0xb 0x4 0x9 0x2 0xb 0x2 0x9>;
interrupt-controller;
compatible = "sifive,plic-1.0.0", "riscv,plic0";
#interrupt-cells = <0x1>;
};
中断是基于每个上下文启用的,上下文的确切含义取决于实现,
但通常偶数上下文(0、2、…)指的是 hart 0、1、… 的 M 模式,
而奇数上下文(1、3、…)指的是 hart 0、1、… 的 S 模式。
例如,要在 hart 0 的 S 模式中启用中断 0x0A,必须切换 base + 0x2000 + 0x80 * context + source / 32 处的第10位。
必须设置优先级和优先级阈值以实际启用中断。 必须将 base + 0x0 + 0x4 * source 设置为任何非零值,并将 base + 0x200000 + 0x1000 * context 设置为低于优先级的任何值。
相关结构体
struct plic_priv {
struct cpumask lmask; // 可以处理plic中断的cpu集合
struct irq_domain *irqdomain; // plic中断控制器对应的中断域
void __iomem *regs; // dts中指定的plic寄存器基地址
unsigned long plic_quirks; // 中断触发模式(edge/level)
unsigned int nr_irqs; // dts中指定的最大中断个数
unsigned long *prio_save; // irqs bitmap 存储中断使能状态位
};
struct plic_handler { // per-cpu变量
bool present;
void __iomem *hart_base; // 每个cpu对应的context基地址
/*
* Protect mask operations on the registers given that we can't
* assume atomic memory operations work on them.
*/
raw_spinlock_t enable_lock; // 中断使能并发保护锁
void __iomem *enable_base; // 中断使能寄存器基地址
u32 *enable_save; // 中断使能标记位的临时存储(suspend/resume时会用到)
struct plic_priv *priv; // plic私有数据
};
__plic_init
分配中断控制器对应的irqdomain,
初始化per-cpu 变量plic_handlers,预先计算好各个中断context寄存器地址
注册plic中断处理函数plic_handle_irq
static int __init __plic_init(struct device_node *node,
struct device_node *parent,
unsigned long plic_quirks)
{
int error = 0, nr_contexts, nr_handlers = 0, i;
u32 nr_irqs;
struct plic_priv *priv;
struct plic_handler *handler;
unsigned int cpu;
priv = kzalloc(sizeof(*priv), GFP_KERNEL);
if (!priv)
return -ENOMEM;
priv->plic_quirks = plic_quirks;
priv->regs = of_iomap(node, 0);
if (WARN_ON(!priv->regs)) {
error = -EIO;
goto out_free_priv;
}
error = -EINVAL;
of_property_read_u32(node, "riscv,ndev", &nr_irqs);
if (WARN_ON(!nr_irqs))
goto out_iounmap;
priv->nr_irqs = nr_irqs;
priv->prio_save = bitmap_alloc(nr_irqs, GFP_KERNEL);
if (!priv->prio_save)
goto out_free_priority_reg;
nr_contexts = of_irq_count(node);
if (WARN_ON(!nr_contexts))
goto out_free_priority_reg;
error = -ENOMEM;
priv->irqdomain = irq_domain_add_linear(node, nr_irqs + 1,
&plic_irqdomain_ops, priv);
if (WARN_ON(!priv->irqdomain))
goto out_free_priority_reg;
for (i = 0; i < nr_contexts; i++) {
struct of_phandle_args parent;
irq_hw_number_t hwirq;
int cpu;
unsigned long hartid;
if (of_irq_parse_one(node, i, &parent)) {
pr_err("failed to parse parent for context %d.\n", i);
continue;
}
/*
* Skip contexts other than external interrupts for our
* privilege level.
*/
if (parent.args[0] != RV_IRQ_EXT) { // 只跟踪记录S模式下的context
/* Disable S-mode enable bits if running in M-mode. */
if (IS_ENABLED(CONFIG_RISCV_M_MODE)) {
void __iomem *enable_base = priv->regs +
CONTEXT_ENABLE_BASE +
i * CONTEXT_ENABLE_SIZE;
for (hwirq = 1; hwirq <= nr_irqs; hwirq++)
__plic_toggle(enable_base, hwirq, 0);
}
continue;
}
error = riscv_of_parent_hartid(parent.np, &hartid);
if (error < 0) {
pr_warn("failed to parse hart ID for context %d.\n", i);
continue;
}
cpu = riscv_hartid_to_cpuid(hartid);
if (cpu < 0) {
pr_warn("Invalid cpuid for context %d\n", i);
continue;
}
/* Find parent domain and register chained handler */
if (!plic_parent_irq && irq_find_host(parent.np)) {
plic_parent_irq = irq_of_parse_and_map(node, i);
if (plic_parent_irq)
irq_set_chained_handler(plic_parent_irq,
plic_handle_irq); // 注册plic中断处理函数
}
/*
* When running in M-mode we need to ignore the S-mode handler.
* Here we assume it always comes later, but that might be a
* little fragile.
*/
handler = per_cpu_ptr(&plic_handlers, cpu);
if (handler->present) {
pr_warn("handler already present for context %d.\n", i);
plic_set_threshold(handler, PLIC_DISABLE_THRESHOLD);
goto done;
}
cpumask_set_cpu(cpu, &priv->lmask); //可以处理plic中断的cpu集合
handler->present = true;
handler->hart_base = priv->regs + CONTEXT_BASE +
i * CONTEXT_SIZE; // 预先算出 hart S特权模式偏移后对应的context基地址
raw_spin_lock_init(&handler->enable_lock);
handler->enable_base = priv->regs + CONTEXT_ENABLE_BASE +
i * CONTEXT_ENABLE_SIZE; // 预先算出hart对应的使能寄存器基地址
handler->priv = priv;
handler->enable_save = kcalloc(DIV_ROUND_UP(nr_irqs, 32),
sizeof(*handler->enable_save), GFP_KERNEL); // suspend/resume阶段临时存储记录中断使能状态
if (!handler->enable_save)
goto out_free_enable_reg;
done:
for (hwirq = 1; hwirq <= nr_irqs; hwirq++) {
plic_toggle(handler, hwirq, 0); // 初始化为关中断
writel(1, priv->regs + PRIORITY_BASE +
hwirq * PRIORITY_PER_ID);// 中断优先级固定为最低优先级1
}
nr_handlers++;
}
/*
* We can have multiple PLIC instances so setup cpuhp state only
* when context handler for current/boot CPU is present.
*/
handler = this_cpu_ptr(&plic_handlers);
if (handler->present && !plic_cpuhp_setup_done) {
cpuhp_setup_state(CPUHP_AP_IRQ_SIFIVE_PLIC_STARTING,
"irqchip/sifive/plic:starting",
plic_starting_cpu, plic_dying_cpu);
plic_cpuhp_setup_done = true;
}
register_syscore_ops(&plic_irq_syscore_ops);
pr_err("%pOFP: mapped %d interrupts with %d handlers for"
" %d contexts.\n", node, nr_irqs, nr_handlers, nr_contexts);
return 0;
out_free_enable_reg:
for_each_cpu(cpu, cpu_present_mask) {
handler = per_cpu_ptr(&plic_handlers, cpu);
kfree(handler->enable_save);
}
out_free_priority_reg:
kfree(priv->prio_save);
out_iounmap:
iounmap(priv->regs);
out_free_priv:
kfree(priv);
return error;
}
plic_handle_irq
plic_handle_irq是所有外设中断的处理入口,它根据hwirq(中断ID)和irqdomain找到具体类型的中断处理函数。
从claim寄存器读取中断ID,就是硬件中断号,调用具体中断处理函数,写回ID到claim寄存器,本次中断就处理完了。
认领中断claim和结束中断complete针对的寄存器是同一个,地址一样。
/*
* Handling an interrupt is a two-step process: first you claim the interrupt
* by reading the claim register, then you complete the interrupt by writing
* that source ID back to the same claim register. This automatically enables
* and disables the interrupt, so there's nothing else to do.
*/
static void plic_handle_irq(struct irq_desc *desc)
{
struct plic_handler *handler = this_cpu_ptr(&plic_handlers);
struct irq_chip *chip = irq_desc_get_chip(desc);
void __iomem *claim = handler->hart_base + CONTEXT_CLAIM;
irq_hw_number_t hwirq;
WARN_ON_ONCE(!handler->present);
chained_irq_enter(chip, desc);
while ((hwirq = readl(claim))) {
int err = generic_handle_domain_irq(handler->priv->irqdomain,
hwirq);
if (unlikely(err))
pr_warn_ratelimited("can't find mapping for hwirq %lu\n",
hwirq);
}
chained_irq_exit(chip, desc);
}
plic_set_affinity
亲和性相关的两个结构体字段
struct irq_common_data {
......
cpumask_var_t smp_affinity // IRQ affinity on SMP. If this is an IPI related irq, then this is the mask of the CPUs to which an IPI can be sent.
cpumask_var_t effective_affinity // The effective IRQ affinity on SMP as some irq chips do not allow multi CPU destinations. A subset of affinity.
.......
}
affinity 多处理器系统上的中断请求亲和性。如果这是与IPI相关的中断请求,那么这是可以发送IPI的CPU的掩码。
effective_affinity 有效的多处理器系统中断请求亲和性,因为某些中断控制器不允许多个CPU作为目标。这是亲和性的一个子集。
该函数为PLIC设置中断亲和性,因为effective_affinity掩码集合中只有一个cpu
所以具体某个外设中断只会亲和到某一个固定cpu上,而不会出现多个cpu都可以响应该中断,争着claim的情况
static int plic_set_affinity(struct irq_data *d,
const struct cpumask *mask_val, bool force)
{
unsigned int cpu;
struct cpumask amask;
struct plic_priv *priv = irq_data_get_irq_chip_data(d);
cpumask_and(&amask, &priv->lmask, mask_val); // amask为参数指定的cpu集合和plic支持处理该中断的cpu集合的交集
// 这里可以看到有效掩码中只会包含一个固定cpu
if (force)
cpu = cpumask_first(&amask);
else
cpu = cpumask_any_and(&amask, cpu_online_mask);
if (cpu >= nr_cpu_ids)
return -EINVAL;
plic_irq_disable(d); // 关闭旧的有效掩码的cpu对应的irq中断
irq_data_update_effective_affinity(d, cpumask_of(cpu)); // 更新有效掩码
if (!irqd_irq_disabled(d)) // 如果cpu侧没有禁止该中断
plic_irq_enable(d); // 打开新的有效掩码的cpu对应的irq中断
return IRQ_SET_MASK_OK_DONE;
}
plic_irq_disable和plic_irq_enable都是操作context enable寄存器中irq对应的的bit位
disable清零,enable置1
static void __plic_toggle(void __iomem *enable_base, int hwirq, int enable)
{
u32 __iomem *reg = enable_base + (hwirq / 32) * sizeof(u32); // 使能
u32 hwirq_mask = 1 << (hwirq % 32);
if (enable)
writel(readl(reg) | hwirq_mask, reg);
else
writel(readl(reg) & ~hwirq_mask, reg);
}
串口中断栈示例
qemu虚拟机串口中断栈
[ 9.465613] CPU: 0 PID: 0 Comm: swapper/0 Not tainted 6.4.7-g078c0f7c1536-dirty #37
[ 9.466334] Hardware name: riscv-virtio,qemu (DT)
[ 9.466692] Call Trace:
[ 9.466921] [<ffffffff8000548e>] dump_backtrace+0x1c/0x24
[ 9.467377] [<ffffffff80830010>] show_stack+0x2c/0x38
[ 9.467811] [<ffffffff8083b1ca>] dump_stack_lvl+0x3c/0x54
[ 9.468223] [<ffffffff8083b1f6>] dump_stack+0x14/0x1c
[ 9.468603] [<ffffffff804e6708>] serial8250_interrupt+0xa6/0xae //串口中断处理函数
[ 9.469319] [<ffffffff80060456>] __handle_irq_event_percpu+0x54/0x142
[ 9.470232] [<ffffffff800605d0>] handle_irq_event+0x3c/0x88
[ 9.471057] [<ffffffff80064106>] handle_fasteoi_irq+0x9c/0x19a
[ 9.471973] [<ffffffff8005f82e>] generic_handle_domain_irq+0x1c/0x2a
[ 9.472969] [<ffffffff8044b6d0>] plic_handle_irq+0x8a/0xf0 // plic中断总入口
[ 9.473783] [<ffffffff8005f82e>] generic_handle_domain_irq+0x1c/0x2a
[ 9.474675] [<ffffffff8044b318>] riscv_intc_irq+0x2e/0x46
[ 9.475407] [<ffffffff8083bca6>] do_irq+0x50/0x84
[ 9.475988] [<ffffffff80003660>] ret_from_exception+0x0/0x64 // 所有广义的异常(中断和异常)入口
[ 9.476593] [<ffffffff8083c57e>] default_idle_call+0x26/0x34
[ 9.477368] [<ffffffff8004a096>] do_idle+0x204/0x224
[ 9.478087] [<ffffffff8004a210>] cpu_startup_entry+0x1a/0x1c
[ 9.478874] [<ffffffff8083c8d0>] kernel_init+0x0/0x10a
[ 9.479617] [<ffffffff80a00672>] arch_post_acpi_subsys_init+0x0/0x18
[ 9.480129] [<ffffffff80a010cc>] console_on_rootfs+0x0/0x68
参考
linux-6.4.7
riscv-plic-1.0.0_rc6