为了研究pagecache相关代码,在嵌入式环境,
利用 ftrace 跟踪 read/write/pagefault/dropcaches 等的过程。
测试命令
# df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
devtmpfs devtmpfs 12101536 0 12101536 0% /dev
tmpfs tmpfs 12217504 128 12217376 0% /tmp
tmpfs tmpfs 12217504 16 12217488 0% /run
/dev/mmcblk0p2 ext4 8256952 12 7837512 0% /mnt/mmc
tmpfs tmpfs 12217504 0 12217504 0% /dev/shm
# echo 3 > /proc/sys/vm/drop_caches
# taskset -c 16 dd if=/mnt/mmc/zerofile of=/mnt/mmc/zerofile2 bs=1k count=8 2>/dev/null
# taskset -c 16 dd if=/mnt/mmc/zerofile of=/mnt/mmc/zerofile2 bs=1k count=8 2>/dev/null
执行路径
读路径:冷读 → PageCache 分配 → 同步预读 → BIO 提交 → blk 层调度。
写路径:PageCache 写入 → 日志元数据更新 → 延迟落盘 I/O。
mmap:共享 PageCache,首次访问触发缺页加载,写时触发 COW。
次要缺页:内存复制更新页表,无硬盘访问。
主要缺页:文件页未缓存,触发硬盘 I/O,加载 PageCache。
日志分析

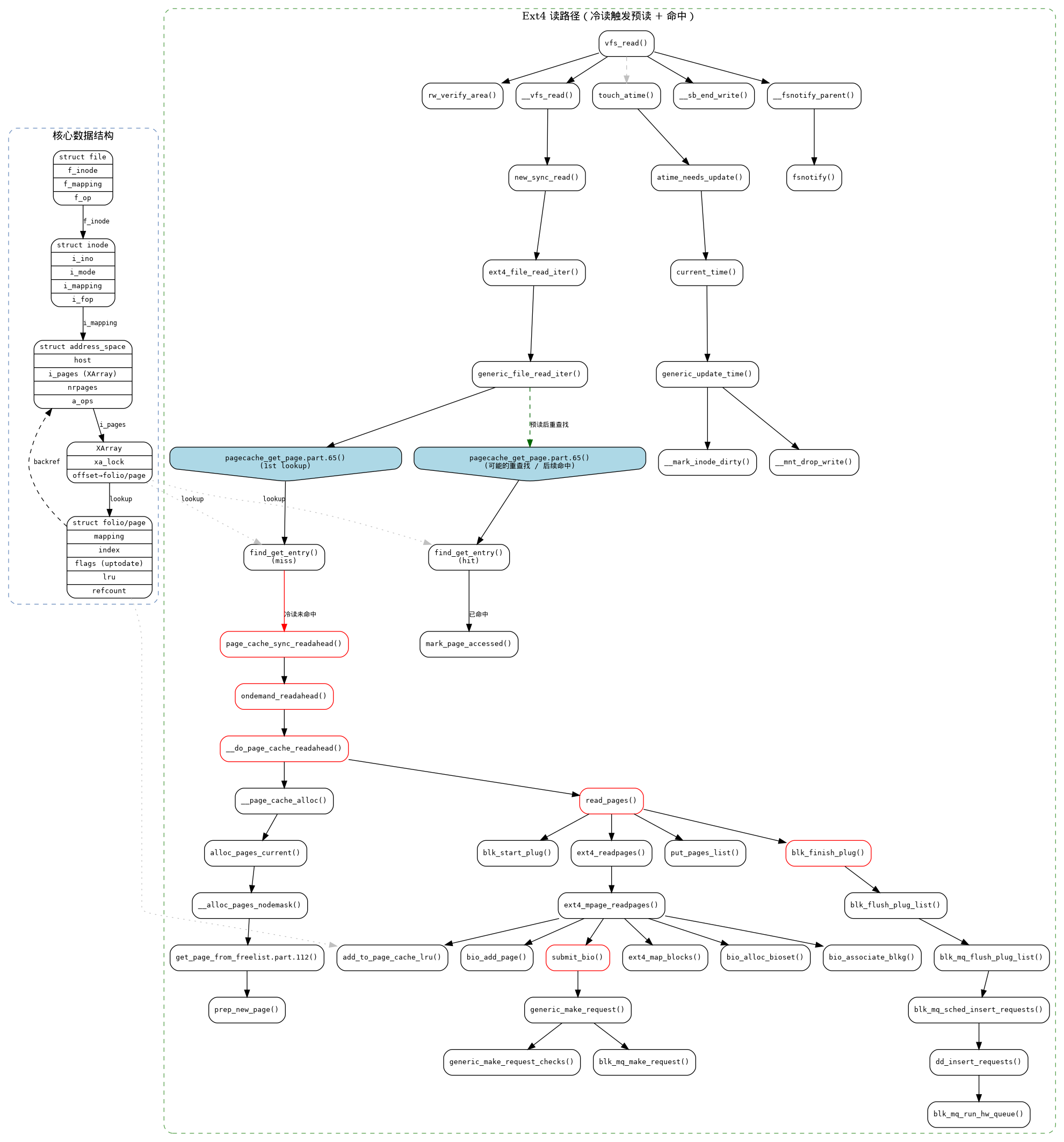
ext4 读路径分析(冷读触发预读)
trace 显示 ext4_file_read_iter 被调用,是从 ext4 文件冷读时的标准调用链。关键路径如下:
vfs_read()
rw_verify_area()
__vfs_read()
new_sync_read()
ext4_file_read_iter()
generic_file_read_iter()
pagecache_get_page.part.59() ### 查找页缓存,首次未命中 ###
page_cache_sync_readahead() # 触发同步预读
ondemand_readahead()
__do_page_cache_readahead()
__page_cache_alloc() # 分配多个页
read_pages()
ext4_readpages()
ext4_mpage_readpages()
add_to_page_cache_lru() ### 加入 page cache ####
ext4_map_blocks() # 逻辑块到物理块映射
ext4_es_lookup_extent()
ext4_ind_map_blocks()
ext4_block_to_path.isra.9()
ext4_get_branch()
ext4_es_insert_extent()
bio_alloc_bioset() # 分配 bio
mempool_alloc()
mempool_alloc_slab()
kmem_cache_alloc()
bio_associate_blkg() # 关联 cgroup
bio_add_page() # 填充 bio 页
submit_bio() # 提交 bio
generic_make_request()
generic_make_request_checks()
blk_mq_make_request()
__blk_queue_split()
__blk_mq_sched_bio_merge() # 尝试合并 bio
dd_bio_merge()
blk_mq_sched_try_merge()
blk_mq_get_request() # 获取请求
blk_account_io_start()
blk_add_rq_to_plug() # 加入 plug 队列
put_pages_list()
blk_finish_plug() # 冲刷 plug 队列
blk_flush_plug_list()
blk_mq_flush_plug_list()
blk_mq_sched_insert_requests()
dd_insert_requests() # deadline 调度器
blk_mq_run_hw_queue() # 唤醒硬件队列
__blk_mq_delay_run_hw_queue()
kblockd_mod_delayed_work_on() # 异步派发 I/O
pagecache_get_page.part.59() # 再次查找,命中并标记访问
mark_page_accessed()
关键点:
- 冷读触发批量预读:首次
pagecache_get_page未命中,触发page_cache_sync_readahead,一次性分配多个页并通过ext4_readpages批量提交 I/O。 - ext4 块映射:
ext4_map_blocks结合 extent tree 查找(ext4_es_lookup_extent)或间接块映射(ext4_ind_map_blocks)完成逻辑块到物理块的转换。 - 块层提交流程:
submit_bio进入generic_make_request,经由blk_mq_make_request将 bio 转换为请求,并利用blk_add_rq_to_plug暂存请求,最后在blk_finish_plug时批量下发到调度器。 - 异步 I/O 完成:
blk_mq_run_hw_queue通过kblockd_mod_delayed_work_on交给 workqueue 异步执行,实际 eMMC 驱动函数(如mmc_mq_queue_rq)不在此堆栈内。
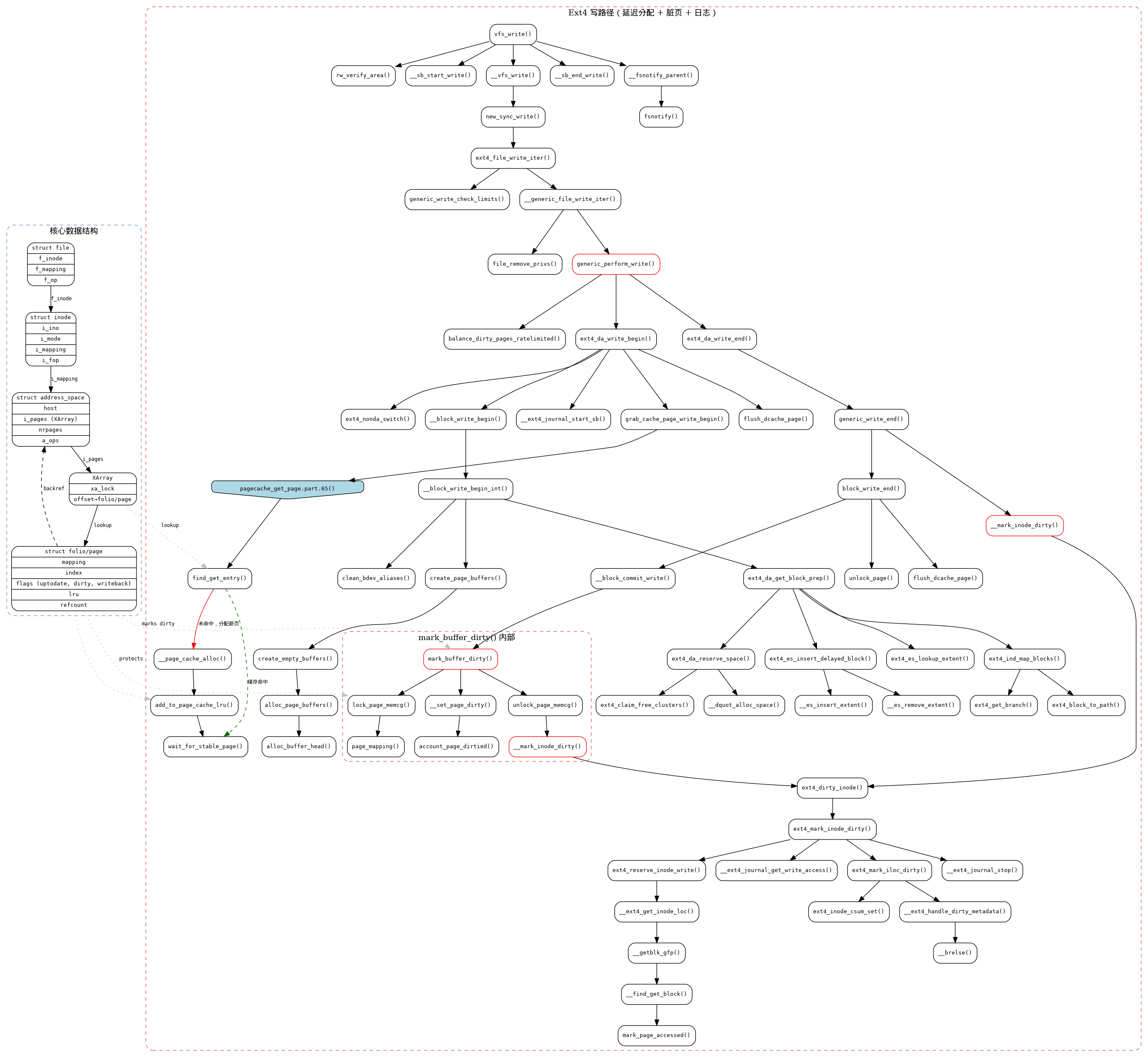
ext4 写路径分析(延迟分配)
写路径 trace 显示:
vfs_write()
rw_verify_area()
__sb_start_write()
__vfs_write()
new_sync_write()
ext4_file_write_iter()
generic_write_check_limits.isra.60()
__generic_file_write_iter()
file_remove_privs()
generic_perform_write()
ext4_da_write_begin() # 延迟分配写开始
grab_cache_page_write_begin()
pagecache_get_page.part.59() ### 获取或创建页缓存页 ###
find_get_entry()
__page_cache_alloc()
alloc_pages_current()
__alloc_pages_nodemask()
get_page_from_freelist()
add_to_page_cache_lru() ### 加入 page cache ####
__add_to_page_cache_locked()
mem_cgroup_try_charge()
__inc_node_page_state()
mem_cgroup_commit_charge()
lru_cache_add()
unlock_page()
__ext4_journal_start_sb() # 开启日志
__block_write_begin() # 准备写入
create_page_buffers()
ext4_da_get_block_prep() # 预留磁盘空间
ext4_es_lookup_extent()
ext4_ind_map_blocks()
ext4_da_reserve_space()
__dquot_alloc_space()
ext4_claim_free_clusters()
ext4_es_insert_delayed_block() # 标记延迟分配块
clean_bdev_aliases()
flush_dcache_page()
flush_dcache_page()
ext4_da_write_end() # 延迟分配写完成
generic_write_end()
block_write_end()
__block_commit_write.isra.41()
mark_buffer_dirty() # 标记 bh 脏
lock_page_memcg()
__set_page_dirty()
account_page_dirtied()
__mark_inode_dirty()
unlock_page()
__mark_inode_dirty() # inode 被标记为脏,唤醒回写线程
ext4_dirty_inode()
ext4_mark_inode_dirty()
ext4_reserve_inode_write()
__ext4_get_inode_loc()
__ext4_journal_get_write_access()
ext4_mark_iloc_dirty()
__ext4_journal_stop()
_cond_resched()
balance_dirty_pages_ratelimited()
__sb_end_write()
关键点:
- 延迟分配:
ext4_da_write_begin中通过ext4_da_reserve_space在内存中预留块并标记延迟分配(ext4_es_insert_delayed_block),实际磁盘空间在稍后的 writeback 时分配。 - 日志保护:
__ext4_journal_start_sb/__ext4_journal_stop将写操作包裹在 ext4 日志事务中,确保持久性。 - 脏页标记与写回:
mark_buffer_dirty标记 buffer head 为脏,__set_page_dirty通过account_page_dirtied更新页脏统计数据。 - inode 脏标记:
ext4_mark_inode_dirty负责更新 inode 元数据(如ext4_reserve_inode_write),并同样通过日志保护。
minor fault(页缓存命中)
当页缓存中已有文件数据时,缺页处理直接建立映射:
do_page_fault()
down_read_trylock()
find_vma()
vmacache_find()
handle_mm_fault()
mem_cgroup_from_task()
__handle_mm_fault()
filemap_map_pages()
PageHuge()
alloc_set_pte() # 设置页表项
add_mm_counter_fast()
page_add_file_rmap()
lock_page_memcg()
unlock_page_memcg()
__sync_icache_dcache()
unlock_page()
... (重复多次 alloc_set_pte)
关键点:
- 无需 I/O:整个路径未出现
__do_fault或readpage,表明所需页面已在页缓存中。 - 批量映射:
filemap_map_pages遍历页缓存中的一批页面,通过alloc_set_pte直接为其建立页表映射,并更新 rmap。 - 性能优势:minor fault 仅涉及内存操作,延迟极低,是 mmap 高效性的关键。
major fault(写时复制)
major fault 发生在需要从磁盘读取数据或进行写时复制时,trace 中显示了 ext4 文件的写时复制流程:
do_page_fault()
down_read_trylock()
find_vma()
handle_mm_fault()
__handle_mm_fault()
do_wp_page() # 写时复制缺页
vm_normal_page()
wp_page_copy()
__anon_vma_prepare() # 准备匿名 VMA
kmem_cache_alloc()
find_mergeable_anon_vma()
alloc_pages_vma() # 分配新物理页
__get_vma_policy()
shmem_get_policy() # 日志中文件策略来自 shmem,但文件为 ext4
get_vma_policy()
__alloc_pages_nodemask()
get_page_from_freelist()
__cpu_copy_user_page() # 拷贝旧页内容
mem_cgroup_try_charge_delay()
add_mm_counter_fast()
ptep_clear_flush() # 清除旧页表项
page_add_new_anon_rmap()
mem_cgroup_commit_charge()
lru_cache_add_active_or_unevictable()
page_remove_rmap() # 移除旧页的 rmap
关键点:
- 写时复制:当对 mmap 共享映射的 ext4 文件进行写操作时,触发
do_wp_page,通过wp_page_copy分配新页并复制数据。 - 匿名页转换:复制后的新页通过
page_add_new_anon_rmap转为匿名页,脱离与文件页缓存的直接关联。 - 页面分配:
alloc_pages_vma分配零阶页,若内存紧张可能涉及内存回收。测试环境系统内存充足,因而trace 中未出现shrink相关调用。 - 元数据更新:更新 rss 计数器、内存 cgroup 统计,并将旧页的脏标记转移到新页(
page_remove_rmap)。
此 major fault 流程展示了 ext4 文件 mmap 写入时的关键路径,确保进程对映射文件的修改不会影响页缓存中的原始数据。
__mark_inode_dirty
第一个 __mark_inode_dirty 调用,内部执行了一条非常关键的路径:
__mark_inode_dirty
├─ locked_inode_to_wb_and_lock_list() // 将 inode 挂入对应 backing device 的脏链表
├─ inode_io_list_move_locked() // 在 wb 的链表上移动该 inode
│ └─ wb_io_lists_populated() // 确认链表是否已初始化
└─ wb_wakeup_delayed() // *** 唤醒回写 worker ***
├─ __msecs_to_jiffies() // 计算延迟时间
├─ queue_delayed_work_on() // 把回写 work 排入 workqueue
│ └─ __queue_delayed_work()
│ └─ add_timer() // 设置定时器,到期后触发 kworker 执行
│ ├─ calc_wheel_index()
│ └─ enqueue_timer()
└─ ... (软中断开关)
交互的子系统:
- VFS inode cache:
locked_inode_to_wb_and_lock_list将 inode 加入 backing device 的脏 inode 链表。 - writeback 框架:
wb_wakeup_delayed→queue_delayed_work_on将wb_workfn作为延迟 work 放入 workqueue,由 kworker 线程执行。 - 实际是由系统里的[kworker/u48:3-events_unbound]代为执行的。
# dd if=/dev/zero of=/mnt/mmc/bigfile3 bs=1M count=4
4+0 records in
4+0 records out
# cd /sys/kernel/tracing/
# cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 3/3 #P:24
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<...>-141 [003] .... 54.177730: <stack trace>
=> do_writepages
=> __writeback_single_inode
=> writeback_sb_inodes
=> __writeback_inodes_wb
=> wb_writeback
=> wb_workfn
=> process_one_work
=> worker_thread
=> kthread
=> ret_from_fork
# ps aux|grep 141
root 141 0.0 0.0 0 0 ? I 00:00 0:00 [kworker/u48:3-events_unbound]
kworker 脏页写回
内核后台 writeback 线程回写脏页的关键路径如下:
wb_workfn()
wb_writeback()
__writeback_inodes_wb()
writeback_sb_inodes()
__writeback_single_inode()
do_writepages()
ext4_writepages() / blkdev_writepages()
generic_writepages()
write_cache_pages() ### 对每个脏页
clear_page_dirty_for_io()
__writepage()
blkdev_writepage()
block_write_full_page()
__block_write_full_page()
__test_set_page_writeback()
submit_bh_wbc()
bio_alloc_bioset()
bio_associate_blkg()
bio_add_page()
submit_bio()
generic_make_request()
blk_mq_make_request()
__blk_mq_sched_bio_merge()
blk_mq_get_request()
blk_account_io_start()
blk_add_rq_to_plug() # 加入 plug 队列
→ 循环处理多个页
blk_finish_plug() # 刷新 plug,批量提交
blk_flush_plug_list()
blk_mq_flush_plug_list()
blk_mq_sched_insert_requests()
dd_insert_requests() # deadline 调度器插入请求
blk_mq_run_hw_queue()
__blk_mq_delay_run_hw_queue()
kblockd_mod_delayed_work_on() # workqueue 异步触发硬件队列
wb_update_bandwidth()
queue_io()
关键点:
- 写回触发:
wb_workfn由内核 writeback 工作队列唤醒,通过wb_writeback选择脏 inode 并逐级回写。 - 页迭代:
write_cache_pages遍历地址空间的脏页,对每页调用__writepage,最终由block_write_full_page生成 bio。 - Plug 机制:
blk_start_plug(trace 开头)与blk_finish_plug配对,将多个相邻的 bio 合并为一个大请求,显著减少块层请求数量。 - 块层提交:
submit_bio进入通用块层,经blk_mq_make_request进入多队列块层,通过 deadline 调度器(dd_insert_requests)进行合并和排序。 - 异步派发:
blk_mq_run_hw_queue并不直接调用驱动,而是通过kblockd_mod_delayed_work_on将实际硬件队列处理交给 workqueue 异步执行,避免阻塞 writeback 上下文。 - 元数据写回:trace 中还包含
ext4_write_inode(如__ext4_get_inode_loc),用于回写 inode 自身元数据,保证文件系统一致性。 - 带宽控制:每轮写回后调用
wb_update_bandwidth更新脏页阈值和写回速率,用于后续后台写回的决策。
fault_around_bytes
# uname -a
Linux buildroot 5.4.74 #19 SMP Tue Apr 28 19:06:33 CST 2026 aarch64 GNU/Linux
#
# cat /sys/kernel/debug/fault_around_bytes
65536
fault_around_bytes 的本质作用是:
控制一次缺页时,内核在目标缺页地址周围“顺带预映射”多少字节的连续页面,以减少后续同一局部区域再次触发 page fault 的次数。
源码注释直接说明了它的设计目标:do_fault_around() 会尝试映射 fault 地址附近的一小段页面,希望这些页面很快还会被访问,从而降低 fault 次数。
do_read_fault() 里只有在 VMA 支持 vm_ops->map_pages() 且 fault_around_bytes >> PAGE_SHIFT > 1 时,
才会先走 do_fault_around(vmf);否则直接退回到普通的 __do_fault(vmf)。
也就是说,fault_around_bytes 决定了这条“先批量映射邻近页”的快速路径是否启用,以及一次尝试覆盖多大的范围。
do_fault_around() 内部会把这个字节数换算成页数 nr_pages,然后把当前 fault 地址按该窗口大小向下对齐,
计算出 start_pgoff 和 end_pgoff,再调用 vma->vm_ops->map_pages(vmf, start_pgoff, end_pgoff) 去批量安装页表项。
它还刻意限制在 同一个 VMA 内、并且不跨越同一个 PTE 页表页边界,因为代码注释里明确说了,这样做是为了只调用一次 map_pages(),同时避免跨页表边界带来的复杂性。
这个变量的默认值是 rounddown_pow_of_two(65536),也就是 64 KiB;并且在 CONFIG_DEBUG_FS 下可以通过 debugfs 动态调整。
设置函数还强制它满足两个约束:
1. 不能大于 PTRS_PER_PTE * PAGE_SIZE
2. 必须是 不超过页大小粒度约束的 2 的幂对齐值,并且最小不会低于 PAGE_SIZE。
源码注释写得很明确:fault_around_bytes 必须向下取整到 do_fault_around() 期望的 page order。
/*
* fault_around_bytes must be rounded down to the nearest page order as it's
* what do_fault_around() expects to see.
*/
static int fault_around_bytes_set(void *data, u64 val)
{
if (val / PAGE_SIZE > PTRS_PER_PTE)
return -EINVAL;
if (val > PAGE_SIZE)
fault_around_bytes = rounddown_pow_of_two(val);
else
fault_around_bytes = PAGE_SIZE; /* rounddown_pow_of_two(0) is undefined */
return 0;
}
可以把它理解成一个“预读式缺页窗口大小”参数:
• 设得大:一次 fault 可能顺带映射更多邻近页,适合线性/局部顺序访问;
• 设得小:prefault 范围缩小,减少一次 fault 的额外工作量,但后续更容易再次 fault;
• 设为 PAGE_SIZE:等价于基本关闭“around”扩展,退化到接近单页 fault 语义。
一句话总结:
fault_around_bytes 决定了文件映射读缺页时,内核会不会以及会在多大范围内“顺带”批量建立邻近页表项;
它的目标是减少重复 page fault,提升局部顺序访问的命中率。
这也就是在trace log里看到的连续调用16次alloc_set_pte的原因。
3582 static vm_fault_t do_read_fault(struct vm_fault *vmf)
3583 {
3584 struct vm_area_struct *vma = vmf->vma;
3585 vm_fault_t ret = 0;
3586
3587 /*
3588 * Let's call ->map_pages() first and use ->fault() as fallback
3589 * if page by the offset is not ready to be mapped (cold cache or
3590 * something).
3591 */
3592 if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) {
3593 ret = do_fault_around(vmf);
3594 if (ret)
3595 return ret;
3596 }
......
drop caches 清理缓存
清理 页面缓存、目录项缓存 和 inode缓存,关键路径如下:
drop_caches_sysctl_handler()
iterate_supers() # 遍历所有超级块
drop_pagecache_sb() # 针对每个超级块,清理其页面缓存
__iget()
invalidate_mapping_pages() # 核心函数:使该超级块下的页面失效
pagevec_lookup_entries() # 在页面缓存中查找候选页面
find_get_entries()
invalidate_inode_page() # 使单个页面失效
page_mapping()
page_mapped()
try_to_release_page() # 尝试释放页面
ext4_releasepage() # 对于 ext4 文件系统
blkdev_releasepage() # 对于块设备文件
try_to_free_buffers()
drop_buffers()
remove_mapping() # 从地址空间中剥离页面(核心步骤)
__remove_mapping()
__delete_from_page_cache() ### 从 page cache 中删除 ###
deactivate_file_page() # 将页面标记为非活跃
__pagevec_release() ### 批量释放已失效的页面 ###
lru_add_drain() # 排空每CPU的LRU缓存
release_pages() # 将页面归还给伙伴系统
mem_cgroup_uncharge_list()
free_unref_page_list()
iput()
drop_slab() # 回收 slab 缓存(dentries 和 inodes)
drop_slab_node()
mem_cgroup_iter()
shrink_slab()
do_shrink_slab() # 遍历各缓存对象的回收函数
super_cache_count() # 获取可用对象数量
super_cache_scan() # 执行真正的回收
trylock_super()
prune_dcache_sb() # 回收目录项缓存
list_lru_walk_one() # 遍历LRU链表中的对象
dentry_lru_isolate()
d_lru_shrink_move()
shrink_dentry_list() # 释放已回收的目录项
__dentry_kill()
__d_drop.part.28()
dentry_unlink_inode()
iput()
dentry_free()
call_rcu()
prune_icache_sb() # 回收 inode 缓存
list_lru_walk_one()
inode_lru_isolate()
dispose_list()
evict() # 驱逐 inode
ext4_evict_inode()
truncate_inode_pages_final()
ext4_clear_inode()
destroy_inode()
__destroy_inode()
call_rcu()
_cond_resched()
关键节点
- 分层回收:操作分为两个主要阶段。
- 第一阶段通过
iterate_supers和invalidate_mapping_pages专注于页面缓存 (Page Cache) 的清理。 - 第二阶段通过
drop_slab和shrink_slab回收因页面释放而变为空闲的 slab 缓存 (Dentries 和 Inodes)。
- 第一阶段通过
- 不同文件系统/对象处理路径不同:
普通文件通过remove_mapping直接剥离页面。
而块设备文件(如日志中的/dev/mmc...)则会进入try_to_release_page->blkdev_releasepage->try_to_free_buffers路径,额外释放缓冲区头。 - 批量释放机制:页面回收不是逐个进行的。
__pagevec_release函数聚集了多个待释放页面,
然后统一调用release_pages将它们归还给伙伴系统,并处理相关的 memcg 结算。 - 处理 THP:
对透明大页进行特殊处理,要么整个大页一起删除,要么完全不删(部分页超出范围的情况index > end)。 - 只处理“干净”页:
drop_caches 的核心逻辑invalidate_mapping_pages会遍历所有 page cache 页面。
一个页面只有通过invalidate_inode_page一整套严格检查后,才会被真正清理,这些检查包括:- 页面不属于任何进程的页表 (!page_mapped(page))。
- 页面不是脏页 (!PageDirty(page))。
- 页面不在回写中 (!PageWriteback(page))。
int invalidate_inode_page(struct page *page) { struct address_space *mapping = page_mapping(page); if (!mapping) return 0; if (PageDirty(page) || PageWriteback(page)) return 0; if (page_mapped(page)) return 0; return invalidate_complete_page(mapping, page); }
- lru list:
deactivate_file_page的作用就是将干净、未映射的文件页移到 inactive LRU 的尾部(加速回收)。
将脏/回写的文件页移到 inactive LRU 的头部并标记 PG_reclaim,促使 flusher 线程优先处理。
当invalidate_inode_page返回 0(页面无法被删除,例如因为脏、回写或被映射),
但页面已被成功锁定且通过了基本检查,则调用deactivate_file_page将其移到 inactive LRU list加速回收。
这是一种“提示”:虽然我现在不能删你,但后续会尽快把你回收掉。
kswapd 内存压力触发回收
trace 显示 kswapd 线程执行 balance_pgdat,触发了标准的后台内存回收流程。
主要包含两个阶段:Slab 缓存回收和 Page Cache/LRU 页回收。关键路径如下:
阶段一:Slab 缓存统计与扫描 (shrink_slab)
balance_pgdat()
pgdat_balanced() # 检查节点是否平衡
shrink_node()
shrink_node_memcg() # 内存组回收
shrink_slab() # 开始 Slab 回收
down_read_trylock() # 获取超级块锁
do_shrink_slab() # 遍历文件系统超级块
super_cache_count() # 统计可回收对象数量
list_lru_count_one() # 计算 LRU 列表中的对象数
super_cache_scan() # 执行实际扫描
trylock_super()
prune_dcache_sb() # 回收 dentry 缓存
list_lru_walk_one()
__list_lru_walk_one()
dentry_lru_isolate() # 隔离待回收 dentry
d_lru_shrink_move()
list_lru_isolate_move()
prune_icache_sb() # 回收 inode 缓存
list_lru_walk_one()
__list_lru_walk_one()
dispose_list()
_cond_resched() # 允许调度
do_shrink_slab() # 其他文件系统 (ext4, nfs, rpc 等)
ext4_es_count() # ext4 扩展属性统计
mb_cache_count() # 块位图缓存统计
阶段二:LRU 页回收 (shrink_inactive_list)
shrink_node()
shrink_list() # 回收非活跃 LRU 链表
shrink_inactive_list()
lru_add_drain() # 刷新本地 LRU 添加队列
isolate_lru_pages() # 从 LRU 链表隔离页面
__isolate_lru_page() # 检查页面状态并隔离
__mod_lruvec_state() # 更新统计计数
shrink_page_list() # 核心页面回收逻辑
_cond_resched()
# 循环处理每个被隔离的页面
page_evictable() # 检查页面是否可回收
page_mapping()
page_referenced() # 检查页面引用计数
page_mapped()
# 分支 A: 匿名页回收 (如堆、栈、共享内存等)
# 匿名页没有关联的文件系统元数据,直接进入 __remove_mapping 流程
__remove_mapping() # 从 Page Cache 移除
workingset_eviction() # 记录工作集事件
__delete_from_page_cache() ### 从 page cache 中删除 ###
unaccount_page_cache_page()
unlock_page()
# 分支 B: 可释放的 Page Cache (如 ext4 文件数据)
try_to_release_page()
ext4_releasepage() # ext4 特定释放逻辑
try_to_free_buffers()
drop_buffers()
free_buffer_head() # 释放 buffer head
kmem_cache_free() # 归还 slab 缓存
__slab_free() # 归还 slab 对象
__remove_mapping()
__delete_from_page_cache() ### 从 page cache 中删除 ###
unlock_page()
mem_cgroup_uncharge_list() # 解除内存组记账
uncharge_page()
uncharge_batch()
__mod_memcg_state()
memcg_check_events()
free_unref_page_list() # 释放物理页帧
free_pcp_prepare()
free_unref_page_prepare.part.80()
free_unref_page_commit()
free_pcppages_bulk() # 批量归还到伙伴系统
pfn_valid() # 验证页帧号有效性
memblock_is_map_memory()
__mod_zone_page_state()
关键点:
- Slab 回收以统计为主:
shrink_slab阶段大量时间消耗在super_cache_count和do_shrink_slab的循环调用上,主要进行list_lru_count_one统计操作。
这表明系统当前可能没有大量的脏 Slab 对象需要紧急回收,或者回收效率很高,大部分时间花在遍历和计数上。 - Page Cache 回收:
shrink_page_list的过程中可以看到大量的page_evictable、page_referenced和__remove_mapping调用。
分支 A 明确代表匿名页回收,分支 B 代表文件页回收。 - Buffer Head 释放:
在try_to_release_page->ext4_releasepage->try_to_free_buffers路径中,
频繁出现free_buffer_head和kmem_cache_free,说明正在回收 ext4 文件的元数据缓存(Buffer Heads),这有助于释放 slab 内存。 - 物理页归还:
free_unref_page_list->free_pcppages_bulk路径中,pfn_valid和memblock_is_map_memory频繁调用,
表明内核正在验证页帧的有效性,并将其归还给伙伴系统(Buddy System)。这是内存回收的最后一步,将物理页标记为可用。
跟踪脚本
#!/bin/sh
set -x
FUNCTION=$1
TRACING_DIR=/sys/kernel/tracing
# 进入 tracing 目录
cd $TRACING_DIR || exit 1
# 1. 停止当前追踪
echo 0 > tracing_on
# 2. 清空原来的 trace 数据和过滤器
echo > trace
echo > set_graph_function
echo > set_graph_notrace
echo > set_ftrace_filter
echo > set_ftrace_notrace
# 3. 设置追踪器为 function_graph
echo function_graph > current_tracer
# 4. 入参函数作为“根函数”展开调用图
#echo "$FUNCTION" >> set_graph_function
echo vfs_read >> set_graph_function
echo vfs_write >> set_graph_function
echo filemap_fault >> set_graph_function
echo do_wp_page >> set_graph_function
echo do_mmap >> set_graph_function
echo do_page_fault >> set_graph_function
# 5. 配置图形输出选项,减少干扰
echo 0 > options/funcgraph-irqs # 不显示中断处理函数
echo 1 > options/funcgraph-proc # 显示进程名(可选)
#echo 32 > max_graph_depth # 限制深度,避免刷屏
echo 1 > options/funcgraph-tail # 显示函数结尾
echo 1 > options/funcgraph-abstime # 显示时间戳
# show process comm pid
echo funcgraph-proc > trace_options
echo funcgraph-abstime > trace_options
# 6. 批量过滤无关函数
# 锁操作
echo mutex_lock >> set_graph_notrace
echo mutex_unlock >> set_graph_notrace
echo down_read >> set_graph_notrace
echo up_read >> set_graph_notrace
echo down_write >> set_graph_notrace
echo up_write >> set_graph_notrace
echo down_write_trylock >> set_graph_notrace
# 调度与等待
echo schedule >> set_graph_notrace
echo io_schedule >> set_graph_notrace
echo schedule_timeout >> set_graph_notrace
echo __wake_up >> set_graph_notrace
echo finish_wait >> set_graph_notrace
echo add_wait_queue >> set_graph_notrace
echo remove_wait_queue >> set_graph_notrace
# RCU
echo rcu_all_qs >> set_graph_notrace
echo rcu_note_context_switch >> set_graph_notrace
# 时间与 atime 更新
echo ktime_get >> set_graph_notrace
echo ktime_get_coarse_real_ts64 >> set_graph_notrace
echo ktime_get_real_seconds >> set_graph_notrace
echo arch_counter_read >> set_graph_notrace
echo current_time >> set_graph_notrace
echo timestamp_truncate >> set_graph_notrace
echo touch_atime >> set_graph_notrace
echo atime_needs_update >> set_graph_notrace
echo generic_update_time >> set_graph_notrace
echo file_update_time >> set_graph_notrace
# 文件系统通知
echo __fsnotify_parent >> set_graph_notrace
echo fsnotify >> set_graph_notrace
# 安全模块
echo security_file_permission >> set_graph_notrace
# 调试辅助函数(你内核里的 update_maxtrace)
echo update_maxtrace >> set_graph_notrace
# 串口 / TTY 驱动(噪声源)
echo uart_write >> set_graph_notrace
echo uart_start >> set_graph_notrace
echo __uart_start >> set_graph_notrace
echo pl011_start_tx >> set_graph_notrace
echo pl011_start_tx_pio >> set_graph_notrace
echo pl011_tx_chars >> set_graph_notrace
echo pl011_tx_char >> set_graph_notrace
echo pl011_read >> set_graph_notrace
echo pl011_stop_tx >> set_graph_notrace
echo redirected_tty_write >> set_graph_notrace
echo uart_write_room >> set_graph_notrace
echo uart_flush_chars >> set_graph_notrace
echo ldsem_down_read >> set_graph_notrace
echo ldsem_up_read >> set_graph_notrace
echo process_echoes >> set_graph_notrace
echo "tty_*" >> set_graph_notrace
echo "n_tty_*" >> set_graph_notrace
# 如果你还看到其他不想看的内核线程函数,可以继续添加
# 7. 关闭块层事件,避免 trace 中插入 bio 事件文本
# [ -f events/block/block_bio_queue/enable ] && echo 0 > events/block/block_bio_queue/enable
# 8. 刷新缓存,确保冷读
echo 3 > /proc/sys/vm/drop_caches
# 9. 开启追踪 → 运行测试 → 关闭追踪
echo 1 > tracing_on
taskset -c 16 dd if=/mnt/mmc/zerofile of=/mnt/mmc/zerofile2 bs=1k count=8 2>/dev/null
taskset -c 16 dd if=/mnt/mmc/zerofile of=/mnt/mmc/zerofile2 bs=1k count=8 2>/dev/null
echo 0 > tracing_on
# 10. 显示结果
cat trace
参考
linux-5.4.74
trace-pagecache-rw-fault-mmap
trace-vfs-do_writepages